# 数据库设计和约束
# 数据库设计
多个表之间的关系分为:
- 一对一:比如人和身份证,这时可以在任意一方添加唯一外键指向另一方的主键。
- 一对多:比如部门和员工,这时在(多的)一方建立外键,指向(一的)一方的主键。
- 多对多:比如学生和课程,多对多关系实现需要借助第三张中间表,中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键。
# 数据库设计范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。注意:
- 要遵循后边的范式要求,必须先遵循前边的所有范式要求。
- 各种范式呈递次规范,越高的范式数据库冗余越小。
几个范式之间的关系如下:
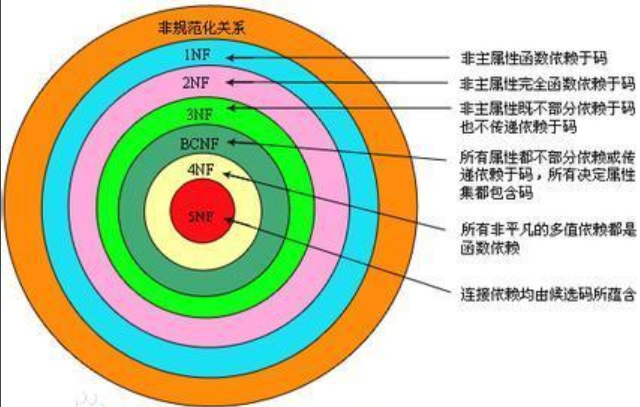
# 概念辨析
- 对象也称为实体型:在现实世界中具有相同性质、遵循相同规则的一类事物的抽象称为对象。对象是实体集数据化的结果,比如学生、老师、课程等是对象。
- 实例:是指对象中的每一个具体的事物,例如学生张三、李四。
- 属性:实体的某一方面特征的抽象表示,例如学生的姓名、性别、班级、年龄等。
- 码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码。
- 主属性:码属性组中的所有属性;非主属性:除码属性组之外的属性。
- 函数依赖:A-->B,如果通过A属性(属性组)的值,可以确定唯一B属性的值,则称B依赖于A。
- 例如:学号-->姓名。 (学号,课程名称) --> 分数
- 完全函数依赖:A-->B, 如果A是一个属性组,则B属性值的确定需要依赖于A属性组中所有的属性值。
- 例如:(学号,课程名称) --> 分数
- 部分函数依赖:A-->B, 如果A是一个属性组,则B属性值得确定只需要依赖于A属性组中某一些值即可。
- 例如:(学号,课程名称) --> 姓名
- 传递函数依赖:A-->B, B -->C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A
- 例如:学号-->系名,系名-->系主任
# 第一范式
第一范式(1NF):每一列都是不可分割的原子数据项。
比如个人属性这样的字段,他可能还细分成年龄,性别等属性。
# 第二范式
2NF是在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)。
第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。
比如(职工号,姓名,职称,项目号,项目名称)中职工号决定姓名,职称,项目号决定项目名称。要解决这样的问题需要拆分,分为职工信息表(职工号,姓名,职称)和项目信息表(项目号,项目名称)。
# 第三范式
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)。
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如(学号,姓名,年龄,性别,所在院校id,院校地址),学号决定它所在院校id,通过院校id来间接决定院校地址,这是传递依赖。
# BCNF范式
在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)。
BCNF要在 3NF 的基础上消除主属性对于码的部分与传递函数依赖。
比如一个公司有若干个仓库,每个仓库只能有一个管理员,一个管理员只在一个仓库中工作,一个仓库可以存放多种物品,多种物品也可以放在不同仓库中,每种物品在其所在仓库中都有相应数量。
如果这样建表(仓库名,管理员,物品名,数量),对吗?
- 先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。
- 某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。
- 如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。
上面案例中:
- 码是(管理员,物品名),(仓库名,物品名)
- 主属性:仓库名、管理员、物品名
- 非主属性:数量
出现上面情况的原因是主属性(仓库名)对于码(管理员,物品名)的部分函数依赖。应该如下拆分表:
- 仓库(仓库名,管理员)
- 库存(仓库名,物品名,数量)
# 约束
对表中的数据进行限定,保证数据的正确性、有效性和完整性。它分为:
- 主键约束(Primay Key Coustraint) 唯一性,非空性
- 外键约束(Foreign Key Counstraint)需要建立两表间的关系并引用主表的列
- 非空约束(NOT NULL)该列不为空
- 唯一约束(Unique Counstraint)唯一性,可以空,但只能有一个
- 默认约束(Default Counstraint)设置列数据的默认值
- 检查约束(Check Counstraint)对该列数据的范围、格式的限制(如:年龄、性别等)
# 主键约束
它的含义是非空且唯一,一张表中只能有一个主键(可能是单个属性,也可能是多个),它们是表中记录的唯一标识。
关于主键的操作如下:
create table stu(
id int primary key,-- 给id添加主键约束
name varchar(20)
);
-- 错误 alter table stu modify id int ;
ALTER TABLE stu DROP PRIMARY KEY;
-- 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
2
3
4
5
6
7
8
9
如果主键是数值类型,可以设置自动增长,这样在添加数据时可自增。
-- 在创建表时,添加主键约束,并且完成主键自增长
create table stu(
id int primary key auto_increment,-- 给id添加主键约束
name varchar(20)
);
-- 删除自动增长
ALTER TABLE stu MODIFY id INT;
-- 添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
2
3
4
5
6
7
8
9
10
# 外键约束
外键 (FK) 是用于在两个表中的数据之间建立和加强链接的一列或多列的组合,可控制可在外键表中存储的数据。如果试图删除主键表中的行或更改主键值,而该主键值与另一个表的外键约束中的值相对应,则该操作将失败。若要成功更改或删除外键约束中的行,必须先在外键表中删除或更改外键数据,这会将外键链接到不同的主键数据。注意,外键可以为null,但不能为不存在的外键值。
它的基本操作为:
-- 在创建表时,可以添加外键
create table 表名(
....
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称)
);
-- 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
-- 创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
-- 通过外键可级联操作(级联更新,级联删除):
ALTER TABLE 表名 ADD CONSTRAINT 外键名称
FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE ;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 非空约束
设置某列的值不能为null,其语法如下:
-- 创建表时添加约束
CREATE TABLE stu(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);
-- 创建表完后,添加非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20) NOT NULL;
-- 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
2
3
4
5
6
7
8
9
10
# 唯一约束
设置某列的值不能重复,唯一约束可以有NULL值,但是只能有一条记录为null,其语法如下:
-- 在创建表时,添加唯一约束
CREATE TABLE stu(
id INT,
phone_number VARCHAR(20) UNIQUE -- 手机号
);
-- 删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;
-- 在表创建完后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;
2
3
4
5
6
7
8
9
# 默认约束
设置该列的默认值,语法如下:
-- 创建表时添加约束
CREATE TABLE student(
ID INT PRIMARY KEY,
NAME VARCHAR (50) NOT NULL UNIQUE,
sex CHAR (2) DEFAULT '女',
);
-- 修改默认值
ALTER TABLE student
CHANGE COLUMN sex
sex CHAR(2) DEFAULT '男';
-- 删除表的约束
ALTER TABLE student
CHANGE COLUMN sex
sex CHAR(2) DEFAULT NULL;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 检查约束
是用来检查数据表中字段值有效性的一种手段,对该列数据的范围、格式的限制(如:年龄、性别等)。语法如下:
-- 创建表时添加约束
CREATE TABLE tb_emp7(
id INT(11) PRIMARY KEY,
name VARCHAR(25),
deptId INT(11),
salary FLOAT,
CHECK(salary>0 AND salary<100),
FOREIGN KEY(deptId) REFERENCES tb_dept1(id)
);
-- 修改表时添加约束
ALTER TABLE tb_emp7 ADD CONSTRAINT check_id CHECK(id>0);
-- 删除表的约束
ALTER TABLE tb_emp7 DROP CONSTRAINT check_id;
2
3
4
5
6
7
8
9
10
11
12
13