本文大部分借鉴了字符编码的前世今生 (opens new window)
# 字符集
每种编程语言都与字符集不可分割的关系,因为写代码本身就需要字符,而计算机只认识0和1,让计算机存储字符就需要在字符和这些0,1数字之间建立一个对应关系。以二战期间摩尔斯码为例来理解这种关系:
# 字符集历史
# 摩尔斯码
摩尔斯码(Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母,数字和标点符号。属于一种早期的数字化通信形式,但是它不用于现代只使用0和1两种状态的二进制代码,它由两种基本信号和不同的间隔时间组成:短促的点信号".",读滴;保持一定时间的长信号"-",读嗒。间隔时间:滴 1t;嗒 3t;滴答间 1t;字符间 3t;字间 7t。
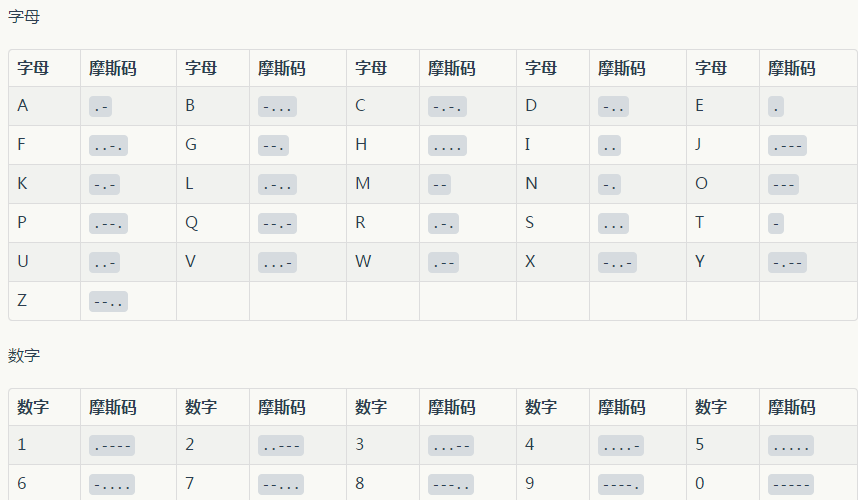
从摩尔斯码理解计算机处理字符的概念,上图中的每个字母和数字就是一个字符,所有字符的集合叫做字符集,而摩尔斯码与字符的对应关系可以理解成是字符编码,把字符转换成对应的电脉冲信号的过程是编码,译码员把接收机收到的脉冲信号转化成点划后译成字符的过程叫做解码。
平时我们打开文档会出现乱码就是因为保存字符的编码方式和解析字符的编码方式不一致,用什么编码方式保存就需要用相应的编码方式解析。对概念有了基本了解后,我们来了解下计算机的字符编码。
# 字符与编码概要
本部分内容出自字符,字节和编码 (opens new window),知识版权归原文所有。
| 阶段 | 系统内码 | 说明 | 字符串在内存中的存放 |
|---|---|---|---|
| 阶段一 | ASCII | 只支持英语,不能显示其他语言 | 一个字节存放一个字符,比如"Hello"在内存中为5个字节。 |
| 阶段二 | ANSI编码(本地化) | 为了使计算机支持更多语言,通常使用0x80-0xFF范围的2个字节来表示1个字符,这时不同的国家和地区制定了不同的标准,由此产生了GB2312,BIG5,JIS等各自的编码标准,这些使用2个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码,简体中文系统下,ANSI编码代表GB2312编码,在日文操作系统下,ANSI编码代表JIS编码。不同的ANSI编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字存储在同一段ANSI编码的文本中 | 每个字符使用一个字节或多个字节来表示,这种方式存放的字符被称作多字节字符,比如"中文123"在内存中为7个字节。 |
| 阶段三 | UNICODE(国际化) | 为了使国际间信息交流更加方便,国际组织制定了UNICODE字符集,为每种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言,跨平台的文本转换处理要求 | 在这个阶段,计算机存放字符时,改为存放每个字符在UNICODE字符集中的序号,目前一般采用2个字节来存放一个序号,这种方式存放的字符被称作宽字节字符,因此上面的"中文123"在内存中存放10个字节。 |
# ASCII码
ASCII (American Standard Code for Information Interchange): (美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,ASCII由美国国家标准学会制定,1967年定案,最初是美国国家标准,后来被国际标准化组织(International Organization for Standardization, ISO)定为国际标准,称为ISO 646标准。

ASCII码一共规定了128个字符,包括了可显示的26个字母(大小写),10个数字,标点符号以及特殊控制符,因为一个字节可以表示256个字符,所以ASCII码只利用了字节的7位,最高位用作奇偶校验。
通常来说定义字符集的会定义一套的字符编码规则,ASCII码是同时定义了字符集及字符编码,Unicode是只定义了字符集,对应的字符编码是UTF-8,UTF-16。
现在再引入两个概念,代码点(Code Point)指ASCII中为字符分配的编号,一个字符只占一个代码点,每个代码点都有一个特定的唯一数值,称为标值。比如a的ASCII码97,97就是a的标值。而代码单元(Code Unit)则是针对编码方法而言,各个编码方式中的单个单元,代码单元的大小等效于特定编码方式的位数,比如在ASCII码中就是7位。
# EASCII:扩展ASCII
随着计算机的普及,计算机开始被西欧国家使用,但在西欧语言中很多字符不在ASCII字符集中,就是他们就想对ASCII码字符集进行扩充,ASCII只使用了字节的前7位,他们想把第8位也利用起来,那么可表示的字符个数就是256,多了一倍,这就是EASCII(Extended ASCII,延伸美国标准信息交换码),它在ASCII码基础上扩充了表格符号,计算符号,希腊字母和特殊的拉丁符号。
但是EASCII码没有形成统一的标准,为了结束混乱的局面,国际标准化组织(ISO)以及国际电工委员会(IEC)联合制定了一系列8位元字符集的标准,叫ISO/IEC 8859。其实这个标准是一组字符集的总称,旗下包含了15个字符集,分别是ISO 8859-1 ~ISO 8859-15,ISO 8859-1又称为Latin-1,是西欧语言的字符集。
# GB2312,GBK,GB18030
计算机普及到中国后,汉字的编码也面临相同的问题,中国国家标准总局1980年发布<<信息交换用汉字编码字符集>>,1981年5月1号开始实施,标准号是GB2312-1980。基本集共收入汉字6763个和非汉字图形字符682个。整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用所在的区和位来对汉字进行编码,称为区位码。它使用两个字节表示。
GB2312所收录的覆盖了中国大陆的99.75%的使用频率字,但对一些罕见的字符没法处理。中国信息技术标准化技术委员会于1995年12月1日制定GBK(汉字内码扩展规范)。该标准同样使用2个字节表示,收录了21003个汉字,向下完全兼容GB2312,向上支持ISO 10646.1国际标准,是一个承上启下过渡的产物。在windows系统中Code Page为936。
国家标准GB18030是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,GB13000等同于国际标准ISO/IEC 10646-2003,也就是Unicode的标准,GB18030有两个标准即2000和2005,其中2000版本收录27533个汉字,2005版本收录了70244个汉字,采用变字节存储(1-4个字节)。
# Unicode和ISO10646
我们有了自己的字符集和字符编码,可世界上还有很多国家拥有自己的字符集,这样不同国家之间交流起来就很困难,于是国际标准化组织(ISO)和多语言软件制造商组成的统一码联盟各自独立开发了ISO/IEC 10646(UCS)和Unicode项目,这两个项目目的是希望用一种字符集来统一全世界所有字符,在1991年前后,两个项目的参与者意识到世界并不需要两个不兼容的字符集,于是他们就编码问题进行了协商,虽然两个项目是独立存在,各自发布各自的标准,但保持兼容。
注意这两个都是包括了世界上多有字符的字符集,其中每一个字符都对应有唯一的编码值(code point),他们并没有规定一个字符究竟是用几个字节表示,只是分配整数给字符的编码表,但它不是字符编码!仅仅是字符集而已,Unicode如何编码,可以是UTF-8,UTF-16甚至是GBK来编码。
UTF( Unicode Transformation Format)编码 和 USC(Universal Coded Character Set) 编码分别是 Unicode 、ISO/IEC 10646 编码体系里面两种编码方式,UCS 分为 UCS-2 和 UCS-4,而 UTF 常见的种类有 UTF-8、UTF-16、UTF-32。UCS-2使用两个定长的字节来表示一个字符,UTF-16使用变长的两个字节,当两个字节无法表示时,会使用四个字节,因此UTF-16可以看作是UCS-2的基础上扩展而来,而UTF-32和USC-4完全等价。
UTF-8的优势是以单字节为单位,用1~4个字节来表示一个字符。从首字节可以判断一个字符的UTF-8编码有几个字节。它的编码看起来是这样的:
0xxxxxxx (0-127)
110xxxxx 10xxxxxx (128-2047)
1110xxxx 10xxxxxx 10xxxxxx (2048-65535)
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (65536-2097151)
2
3
4
UTF-8其一兼容了ASCII码,在数据传输和存储过程中节省了空间,其二是UTF-8不用考虑大小端问题,这两点都是UTF-16的劣势。不过对于中文字符,UTF-8需要3个字节,UTF-16需要2个字节。而UTF-16优点是计算字符串长度,执行索引操作时速度会很快。Java内部使用UTF-16,Python2使用ASCII码字符集,Python3使用UTF-8。UTF-8编码在互联网领域更加广泛。
windows平台保存文件时默认的字符编码是ANSI,它是根据不同的国家地区有不一样的结果,比如简体中文windows中ANSI编码代表了GBK编码,日文windows中ANSI编码代表Shift_JIS编码。
# 大端与小端
大小端指的是数据在存储器中的存放顺序,大端模式下,数据的高字节在前,与人类的读写法一致,小端模式下,数据的高字节在后。比如十六进制0x1234567在内存中存储为:

当处理字节大于一个字节的时候就会有大小端问题,x86和一般OS(windows,FreeBSD,Linux)使用的都是小端模式,MacOS是大端模式。由于UTF-8编码单元是1个字节,所以不用考虑字节序问题,而UTF-16是用2个字节来编码Unicode字符,所以需要考虑这个问题。
# C++和Java中的字符与字节
本部分内容出自字符,字节和编码 (opens new window),知识版权归原文所有。
| 类型或操作 | C++ | Java |
|---|---|---|
| 字符 | wchar_t | char |
| 字节 | char | byte |
| ANSI字符串 | char[] | byte[] |
| UNICODE字符串 | wchar_t[] | String |
| 字节串->字符串 | mbstowcs(),MultiByteToWideChar() | string = new String(bytes,"encoding") |
| 字符串->字节串 | wcstombs(),WideCharToMultiByte() | bytes = string.getBytes("encoding") |
注意:
- Java中的char代表一个"UNICODE字符(宽字节字符)",而C++中的char代表一个字节。
- MultiByteToWideChar()和WideCharToMultiByte()是WindowsAPI函数。
# C++的编码
使用标准C++编程时,默认的编码方式是ASCII,为了处理Unicode,C++提供了宽字符wchar_t来处理函数。
# 通用字符名
C++实现支持一个基本的源字符集,即可用来编写源代码的字符集。还有一个基本的执行字符集,它包括程序执行期间可处理的字符(如从文件中读取或显示在屏幕上的字符),增加了一些字符,比如退格和振铃。C++标准还允许实现提供扩展源字符集和扩展执行字符集。那些被作为字母的额外字符也可用用于标识符名称中。C++有一种表示这种特殊字符的机制,它独立于任何特定的键盘,使用通用字符名(universal character name)。
通用字符名的用法类似于转义序列。通用字符名以\u或\U打头,\u后面是8个十六进制位,\U后面则是16个十六进制位,这些位表示的是字符ISO 10646码点。如果所用实现支持扩展字符,则可以在标识符(字符常量)和字符串中使用通用字符名。
int main()
{
setlocale(LC_ALL,"German");
int k\u00F6rper=10;
cout << k\u00F6rper << endl;
wcout << L"Let them eat g\u00E2teau.\n";
}
//注意cout是以当前系统默认编码来显示的,wcout使用前需要设置locale,否则默认C locale,不能显示中文。
//要显示德文最好将系统的区域设成德文,而不是用上面的方法,因为上面实测输出的结果不是德文。
2
3
4
5
6
7
8
9
10
请注意C++使用术语"通用编码名",而不是"通用编码",这是因为应将\u00F6解释为"Unicode码点为U-00F6的字符"。支持Unicode的编译器知道,这表示相应的字符,但无需使用内部编码。无论计算机使用时ASCII还是其他编码系统,都在内部表示该字符。同样,在不同的系统中使用不同的编码来表示该字符。在源代码中,可使用适用于所有系统的通用编码名,而编译器将根据当前系统使用合适的内部编码来表示它。
# char和wchar_t
程序可能需要处理的字符集无法用一个8位字节表示,对于这种情况,C++的处理方式有两种:
- 如果大型字符集是实现的基本字符集,则编译器厂商可以将char定义为一个16位的字节或更长的字节。
- 一种实现可以同时支持一个小型基本字符集和一个较大的扩展字符集。
8位char可以表示基本字符集,另一种类型wchar_t(宽字符类型)可以表示扩展字符集。wchar_t是一种整数类型,它有足够的空间,但是对底层类型的选取决于实现,有的系统是unsigned short,有的则为int。在不同平台上它的字长还可能不一致,windows上2个bytes,linux上4个bytes,这样导致windows上对于多于2字节的字符处理存在问题,后来微软不得不提供一些额外的API来处理这种情况,现在新的标准中明确了各种编码存储的字长,处理起Unicode更加明确。比如在自身层面,引入char16_t和char32_t来明确UTF-16和UTF-32编码方案对应的存储类型,在库中多了u16string和u32string。
# 具体实现方法
本部分内容出自字符,字节和编码 (opens new window),知识版权归原文所有。
声明一段字符串变量:
// ANSI 字符串,内容长度 7 字节
char sz[20] = "中文123";
// UNICODE 字符串,内容长度 5 个 wchar_t(10 字节)
wchar_t wsz[20] = L"\x4E2D\x6587\x0031\x0032\x0033";
2
3
4
5
UNICODE字符串I/O操作,字符与字节的转换操作:
// 运行时设定当前 ANSI 编码,VC 格式
setlocale(LC_ALL, ".936");
// GCC 中格式
setlocale(LC_ALL, "zh_CN.GBK");
// Visual C++ 中使用小写 %s,按照 setlocale 指定编码输出到文件
// GCC 中使用大写 %S
fwprintf(fp, L"%s\n", wsz);
// 把 UNICODE 字符串按照 setlocale 指定的编码转换成字节
wcstombs(sz, wsz, 20);
// 把字节串按照 setlocale 指定的编码转换成 UNICODE 字符串
mbstowcs(wsz, sz, 20);
2
3
4
5
6
7
8
9
10
11
12
13
14
在Visual C++中,UNICODE字符串常量有更简单的表示方法。如果源程序的源码与当前默认ANSI编码不符,则需要使用#pragma setlocale,告诉编译器程序使用的编码:
// 如果源程序的编码与当前默认 ANSI 编码不一致,
// 则需要此行,编译时用来指明当前源程序使用的编码
#pragma setlocale(".936")
// UNICODE 字符串常量,内容长度 10 字节
wchar_t wsz[20] = L"中文123";
2
3
4
5
6
主要#pragma setlocale与setlocale(LC_ALL,"")的作用是不同的,#pragma setlocale在编译时起作用,setlocale()在运行时起作用。
# Java中的编码
# Java中的实现
本部分内容出自字符,字节和编码 (opens new window),知识版权归原文所有。
字符串类 String 中的内容是 UNICODE 字符串:
// Java 代码,直接写中文
String string = "中文123";
// 得到长度为 5,因为是 5 个字符
System.out.println(string.length());
2
3
4
5
字符串I/O操作,字符与字节转换操作。在Java包java.io.*中,以"Stream"结尾的类一般是用来操作"字节串"的类,以"Reader","Writer"结尾的类一般是用来操作"字符串"的类。
// 字符串与字节串间相互转化
// 按照 GB2312 得到字节(得到多字节字符串)
byte [] bytes = string.getBytes("GB2312");
// 从字节按照 GB2312 得到 UNICODE 字符串
string = new String(bytes, "GB2312");
// 要将 String 按照某种编码写入文本文件,有两种方法:
// 第一种办法:用 Stream 类写入已经按照指定编码转化好的字节串
OutputStream os = new FileOutputStream("1.txt");
os.write(bytes);
os.close();
// 第二种办法:构造指定编码的 Writer 来写入字符串
Writer ow = new OutputStreamWriter(new FileOutputStream("2.txt"), "GB2312");
ow.write(string);
ow.close();
/* 最后得到的 1.txt 和 2.txt 都是 7 个字节 */
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
如果 java 的源程序编码与当前默认 ANSI 编码不符,则在编译的时候,需要指明一下源程序的编码。比如:
E:\>javac -encoding BIG5 Hello.java
以上需要注意区分源程序的编码与 I/O 操作的编码,前者是在编译时起作用,后者是在运行时起作用。