# 简介
这篇文章中有两个案例:
- 通过百度搜索结果来判断两个物体之间的关联。
- 获取人工智能相关的论文及简介。
# 通过百度判断关联
本文是以华为和其他公司的关联度为例。通过一些关系词以及两个实体是否同时出现在标题和详情中来计算关联度。
# 获取人工智能论文
# 目标数据
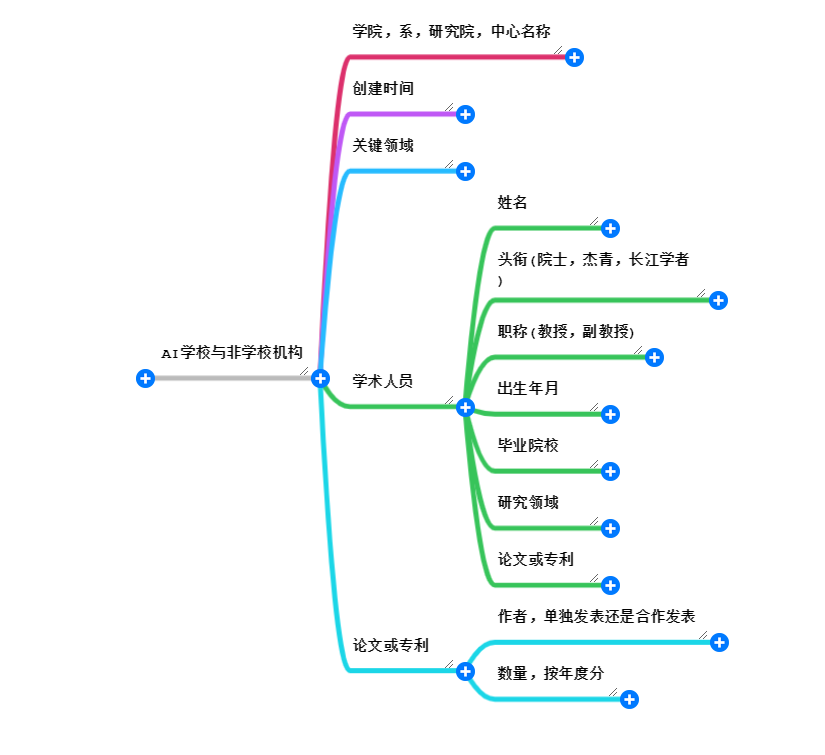
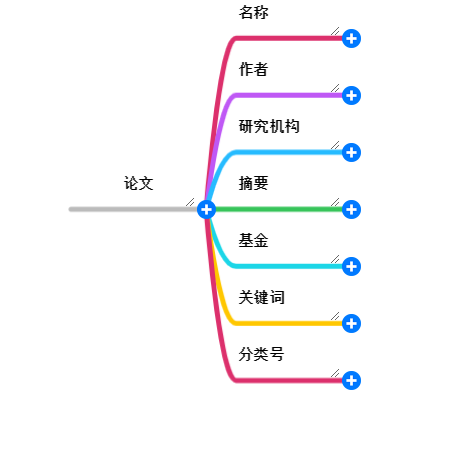
# 获取过程
搜人工智能关键词结果:
- 上面网站是 14762
- 万方官网是 17947
- 知网官网是 15134
实际抓下来的文章列表是 14762条,细节内容是14720条。
# 结果分析
专业中带"智能":
- 文档里一共有94所学校
- 分析后专业里带智能的学校有132所
- 原无我有:60所
- 原有我无:52所
专业中不带"智能":
- 原有我无:30所
- 原无我有:340所
# 程序记录
# items
定义的数据传输对象:
import scrapy
class ArtintelligencecompanyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class BaiduSearchItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nodeName = scrapy.Field();
detailInfo = scrapy.Field();
totalRelatedDegree = scrapy.Field();
pass
class GetArticleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field();
author = scrapy.Field();
department = scrapy.Field();
sourceDatabase = scrapy.Field();
degreeAwardingTime = scrapy.Field();
referencedNumber = scrapy.Field();
downloadNumber = scrapy.Field();
pass
class GetWanFangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field();
authorInfo = scrapy.Field();
shortInfo = scrapy.Field();
keyword = scrapy.Field();
href = scrapy.Field();
pass
class GetWanFangDetailItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
ID = scrapy.Field();
title = scrapy.Field();
shortInfo = scrapy.Field();
author = scrapy.Field();
specialty = scrapy.Field();
degree = scrapy.Field();
school = scrapy.Field();
teacherName = scrapy.Field();
grantTime = scrapy.Field();
studyDirection = scrapy.Field();
language = scrapy.Field();
classification = scrapy.Field();
keyword = scrapy.Field();
classificationByMachine = scrapy.Field();
keywordByMachine = scrapy.Field();
fundProject = scrapy.Field();
pass
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# pipelines
爬取结果的处理:
import pymysql
class ArtintelligencecompanyPipeline(object):
database = {
'host':'maria',
'database':'pythonrepo',
'user':'root',
'password':'666666',
'charset':'utf8'
}
def __init__(self):
self.db = pymysql.connect(**self.database)
self.cursor = self.db.cursor();
def close_spider(self,spider):
print("------关闭数据库资源------")
self.cursor.close()
self.db.close()
def process_item(self, item, spider):
#if spider.name == "companyName":
print("hi,this is common pipelines")
return item
class BaiduPipeline(ArtintelligencecompanyPipeline):
def process_item(self, item, spider):
if item['totalRelatedDegree'] > 0 :
for i in item["detailInfo"]['relatedDegree']:
self.cursor.execute("insert into HuaweiRelatedNode(nodeName,infoTitle,href,shortInfo,relatedDegree) values(%s,%s,%s,%s,%s)",(item['nodeName'],item["detailInfo"]['infoTitle'][i],item["detailInfo"]['infoTitleHref'][i],item["detailInfo"]['infoSummary'][i],item["detailInfo"]['relatedDegree'][i]))
else:
self.cursor.execute("insert into HuaweiRelatedNode(nodeName) values(%s)",(item["nodeName"]))
self.db.commit()
return item
class GetArticlePipeline(ArtintelligencecompanyPipeline):
def process_item(self, item, spider):
pass
class GetWanFangPipeline(ArtintelligencecompanyPipeline):
def process_item(self, item, spider):
itemNum = len(item['title'])
if itemNum > 0 :
print("==========Input Data begin:===========")
for i in range(0,itemNum):
self.cursor.execute("insert into WanFangArticle(title,authorInfo,shortInfo,keyword,href) values(%s,%s,%s,%s,%s)",(item['title'][i],item["authorInfo"][i],item["shortInfo"][i],item["keyword"][i],item["href"][i]))
self.db.commit()
return item
class GetWanFangDetailPipeline(ArtintelligencecompanyPipeline):
def getInitArticleList(self):
self.cursor.execute("select id,href from WanFangArticle where id not in (select id from WanFangArticleDetail)")
return self.cursor
def process_item(self, item, spider):
if "title" in item and len(item["title"]) > 0 :
self.cursor.execute("insert into WanFangArticleDetail(id,title,shortInfo,author,specialty,degree,school,teacherName,grantTime,studyDirection,language,classification,keyword,classificationByMachine,keywordByMachine,fundProject) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["ID"],item['title'][0].replace(u'\xa0', u''),item["shortInfo"][0],item["author"][0].replace(u'\xa0', u''),item["specialty"][0].replace(u'\xa0', u''),item["degree"][0].replace(u'\xa0', u''),item['school'][0].replace(u'\xa0', u''),item["teacherName"][0].replace(u'\xa0', u''),item["grantTime"][0].replace(u'\xa0', u''),item["studyDirection"][0].replace(u'\xa0', u''),item["language"][0].replace(u'\xa0', u''),item['classification'][0],item["keyword"][0],item["classificationByMachine"][0],item["keywordByMachine"][0],item["fundProject"][0]))
#else :
# self.cursor.execute("insert into WanFangArticleDetail(title) values(%s)",('none'))
self.db.commit()
return item
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# settings
项目中的设置:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 2
DOWNLOAD_TIMEOUT = 1800
CONCURRENT_REQUESTS_PER_IP = 16
DEFAULT_REQUEST_HEADERS = {
# "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'ArtIntelligenceCompany.pipelines.ArtintelligencecompanyPipeline': 300,
}
HTTPERROR_ALLOWED_CODES = [403,404,500]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# spiders
# BaiduSearch
BaiduSearch.py 爬虫用百度来分析两个实体之间的关联:
import scrapy
from ArtIntelligenceCompany.items import BaiduSearchItem
import csv
class BaidusearchSpider(scrapy.Spider):
name = 'BaiduSearch'
allowed_domains = ['www.baidu.com']
#基本url
base_urls = 'http://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=华为+'
start_urls = [base_urls]
custom_settings = {
'ITEM_PIPELINES':{'ArtIntelligenceCompany.pipelines.BaiduPipeline': 300}
}
#要查找的页面
searchPage=0
#最多查找几页,默认查找3页
maxPageNum=2
#关系节点列表
targetNode=[]
mainNode="华为"
#当前关系节点名称
currentNodeName=""
# keyword集合
keywordSet=[
"和",
"与",
"合作",
"伙伴",
]
# 定义搜索规则的权重
ruleWeight={
"BothInTitle":80,
"BothInSummary":60,
"TwoInTitleAndSummary":40,
"FindKeyWordInTitle":20,
"FindKeyWordInSummary":10,
}
#从文件中获取关系节点
def getTargetNode(self):
with open("targetNode.csv") as f:
#with open("DebugFile/debuglist.csv") as f:
reader=csv.reader(f)
self.header=next(reader)
for row in reader:
self.targetNode.append(row)
#从关系节点数组获取最新的关系节点
def getLatestNode(self):
self.searchPage=0
self.currentNodeName=self.targetNode.pop(0)[0]
return self.currentNodeName;
#初始化相关信息
def __init__(self, *args, **kwargs):
super(BaidusearchSpider, self).__init__(*args, **kwargs)
self.getTargetNode()
self.start_urls[0] += self.getLatestNode();
#调试相关信息
def DebugLog(self,str):
with open(r'DebugFile/debuglog.txt', 'x') as fp:
fp.write(str)
# 查找一个字符串在另一个字符串中出现的次数
def findStrNums(self,sourceStr,TargetStr):
nums=0
findStartPos=sourceStr.find(TargetStr)
#print("----------source str:%s,target str:%s,find pos:%s--------------" % (sourceStr,TargetStr,findStartPos) )
if(findStartPos!=-1):
nums+=1
while findStartPos<len(sourceStr):
findStartPos=sourceStr.find(TargetStr,findStartPos+1)
if(findStartPos!=-1):
nums+=1
else:
return nums
return nums
def parse(self, response):
# 每个关系节点开始找
item = BaiduSearchItem()
item["nodeName"]=self.currentNodeName
item["detailInfo"]={}
detailBlock = response.xpath('//div[@id="content_left"]/div/div[@class="result"]')
item["detailInfo"]['infoTitle'] = detailBlock.xpath('./h3[@class="c-title"]/a').xpath('string(.)').extract();
item["detailInfo"]['infoTitleHref'] = detailBlock.xpath('./h3[@class="c-title"]/a/@href').extract();
# item["detailInfo"]['infoTitleKeyword'] = detailBlock.xpath('./h3[@class="c-title"]/a/em').extract();
item["detailInfo"]['infoSummary'] = detailBlock.xpath('./div').xpath('string(.)').extract();
# item["detailInfo"]['infoSummaryKeyword'] = detailBlock.xpath('./div[@class="c-summary c-row "]/em').extract();
item["detailInfo"]['relatedDegree'] = {}
item['totalRelatedDegree']= 0
#self.DebugLog(response.text)
maxEachPageItem = len(item["detailInfo"]['infoTitle'])
#for i in range(0,maxEachPageItem):
# print("----------%s----info:------" % i+item["detailInfo"]['infoSummary'][i])
if maxEachPageItem > 0:
for i in range(0,maxEachPageItem):
relatedDegree=0
if self.findStrNums(item["detailInfo"]['infoTitle'][i],self.mainNode)> 0 and self.findStrNums(item["detailInfo"]['infoTitle'][i],self.currentNodeName)>0:
relatedDegree+=self.ruleWeight["BothInTitle"]
for oneWord in self.keywordSet:
relatedDegree+=self.findStrNums(item["detailInfo"]['infoTitle'][i],oneWord)*self.ruleWeight["FindKeyWordInTitle"]
if self.findStrNums(item["detailInfo"]['infoSummary'][i],self.mainNode)> 0 and self.findStrNums(item["detailInfo"]['infoSummary'][i],self.currentNodeName)>0:
relatedDegree+=self.ruleWeight["BothInSummary"]
for oneWord in self.keywordSet:
relatedDegree+=self.findStrNums(item["detailInfo"]['infoSummary'][i],oneWord)*self.ruleWeight["FindKeyWordInSummary"]
if relatedDegree == 0:
if (self.findStrNums(item["detailInfo"]['infoTitle'][i],self.mainNode) > 0 ^ self.findStrNums(item["detailInfo"]['infoSummary'][i],self.currentNodeName) > 0) or (self.findStrNums(item["detailInfo"]['infoSummary'][i],self.mainNode) > 0 ^ self.findStrNums(item["detailInfo"]['infoTitle'][i],self.currentNodeName) > 0):
relatedDegree += self.ruleWeight["TwoInTitleAndSummary"]
if relatedDegree != 0 :
item["detailInfo"]['relatedDegree'][i]=relatedDegree
item['totalRelatedDegree']+=relatedDegree
else:
print("---------item is null!------------")
if self.searchPage > 0 and item['totalRelatedDegree'] ==0:
print("-------------%s在新的一页%s没有找到要找项--------------------" % (self.currentNodeName,self.searchPage))
else:
yield item
if item['totalRelatedDegree'] != 0 and self.searchPage < self.maxPageNum:
self.searchPage += 1
print("------------current node:%s--------page:%s---------" % (self.currentNodeName,self.searchPage))
yield scrapy.Request(self.start_urls[0]+'pn='+str(self.searchPage*10),callback=self.parse)
else:
if len(self.targetNode) > 0:
self.start_urls[0]=self.base_urls+self.getLatestNode()
print("--------new related node:%s !begin---------" % self.currentNodeName)
yield scrapy.Request(self.start_urls[0],callback=self.parse)
return
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
# getArticle
getArticle 爬虫本来是要获取知网的论文列表,模拟登陆知网,但是没有成功:
import scrapy
from selenium import webdriver
from ArtIntelligenceCompany.items import GetArticleItem
import time
class GetarticleSpider(scrapy.Spider):
name = 'getArticle'
allowed_domains = ['kns.cnki.net']
start_urls = ['https://kns.cnki.net/kns/brief/brief.aspx?pagename=ASP.brief_default_result_aspx&isinEn=0&dbPrefix=CDMD&dbCatalog=%e4%b8%ad%e5%9b%bd%e4%bc%98%e7%a7%80%e5%8d%9a%e7%a1%95%e5%a3%ab%e5%ad%a6%e4%bd%8d%e8%ae%ba%e6%96%87%e5%85%a8%e6%96%87%e6%95%b0%e6%8d%ae%e5%ba%93&ConfigFile=SCDBINDEX.xml&research=off&keyValue=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&S=1&sorttype=(FFD%2c%27RANK%27)+desc&queryid=25']
custom_settings = {
'ITEM_PIPELINES':{'ArtIntelligenceCompany.pipelines.GetArticlePipeline': 300}
}
headers = {
"Referer":"https://login.cnki.net/login/",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",
}
def __init__(self):
self.login_cookies = []
def get_cookies(self):
cookies=[]
startOptions=webdriver.chrome.options.Options()
startOptions.headless=True
startOptions.add_argument("--no-gpu")
startOptions.add_argument("--no-sandbox")
self.browser=webdriver.Chrome(executable_path="/home/jovyan/work/TestScrappy/ArtIntelligenceCompany/chromedriver",chrome_options=startOptions)
time.sleep(3)
self.browser.get("https://login.cnki.net/login/?platform=kns&ForceReLogin=1&ReturnURL=https://www.cnki.net/")
username = self.browser.find_element_by_xpath('//input[@id="TextBoxUserName"]')
username.send_keys('user')
password = self.browser.find_element_by_xpath('//input[@id="TextBoxPwd"]')
password.send_keys('password')
commit = self.browser.find_element_by_xpath('//div[@class="btn"]/a[@id="Button1"]')
commit.click()
time.sleep(5)
if self.browser.title == "中国知网":
self.login_cookies = self.browser.get_cookies()
print("登录成功!")
else:
print("登录失败!")
pass
def start_requests(self):
self.get_cookies()
print("========login cookies========\n",self.login_cookies)
return [scrapy.Request(self.start_urls[0],headers=self.headers,cookies=self.login_cookies,callback=self.parse)]
def parse(self, response):
print("===============Enter parse function=============")
print(response.text)
item = GetArticleItem()
infoList = response.xpath('//table[@class="GridTableContent"]/tbody/tr[@class!="GTContentTitle"]')
print(infoList)
item["title"]= infoList.xpath('./td[1]/a').xpath('string(.)').extract()
print(item)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# getWanFang
getWanFang.py 爬虫获取论文的列表:
import scrapy
from ArtIntelligenceCompany.items import GetWanFangItem
import time
import os
class GetwanfangSpider(scrapy.Spider):
name = 'getWanFang'
allowed_domains = ['lib-wf.sstir.cn']
start_urls = ['http://lib-wf.sstir.cn/S/paper.aspx?q=%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd+dbid%3aWF_XW&o=sortby+CitedCount+CoreRank+date+relevance%2fweight%3d5&f=SimpleSearch&n=10&p=1']
myBase_urls = "http://lib-wf.sstir.cn/S/paper.aspx?q=%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd+dbid%3aWF_XW&o=sortby+CitedCount+CoreRank+date+relevance%2fweight%3d5&f=SimpleSearch&n=10&p="
custom_settings = {
'ITEM_PIPELINES':{'ArtIntelligenceCompany.pipelines.GetWanFangPipeline': 300}
}
#没有找到的页
notFindPage=[]
#当前爬取的第几页
pageNum=1
#最大尝试次数
MaxTryNum=20
#已经尝试了几次
triedNum=0
def parse(self, response):
#print(response.text)
detailBlock = response.xpath('//div[@id="content_div"]/div/div')
item = GetWanFangItem()
item["title"]=detailBlock.xpath('./ul[@class="list_ul"]/li[@class="title_li"]/a[not(@title="下载全文")]').xpath('string(.)').extract();
item["href"]=detailBlock.xpath('./ul[@class="list_ul"]/li[@class="title_li"]/a[not(@title="下载全文")]/@href').extract();
item["authorInfo"]=detailBlock.xpath('./ul[@class="list_ul"]/li[@class="greencolor"]').xpath('string(.)').extract();
item["shortInfo"]=detailBlock.xpath('./ul[@class="list_ul"]/li[@class="zi"]').xpath('string(.)').extract();
item["keyword"]=detailBlock.xpath('./ul[@class="list_ul"]/li[@class="zi"]/p[@class="greencolor"]').xpath('string(.)').extract();
#print("============================output result:=========================")
#print(item)
if len(item["title"])>0 :
self.triedNum=0
print("------------------Get Page:%d-------------------" % self.pageNum)
self.pageNum+=1
maxEachPageItem=len(item["shortInfo"])
#remove keyword from shortInfo
for i in range(0,maxEachPageItem):
infoStr=item["shortInfo"][i]
if infoStr.find("...") >=0 :
item["shortInfo"][i]=infoStr[0:infoStr.find("...")]
yield item
self.start_urls[0]=self.myBase_urls+str(self.pageNum)
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
#print("----------%s----info:------" % i+item["shortInfo"][i])
else:
if self.triedNum<self.MaxTryNum:
self.triedNum+=1
print("------------------Page:%d Have tried:%d Times-------------------" % (self.pageNum,self.triedNum))
time.sleep(self.triedNum*3)
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
else:
if self.pageNum < 1478 :
self.notFindPage.append(self.pageNum)
self.pageNum+=1
self.start_urls[0]=self.myBase_urls+str(self.pageNum)
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
else :
print(self.notFindPage)
filepath=os.path.dirname(__file__)+r'/notfindpage.txt'
print("调试文件位置:",filepath)
if os.path.exists(filepath):
os.remove(filepath)
with open(filepath, 'x' , encoding='utf-8') as fp:
fp.writelines(self.notFindPage)
print("==============search over!===============")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# GetWanFangDetail
GetWanFangDetail.py 爬虫获取论文的细节内容:
import scrapy
from ArtIntelligenceCompany.items import GetWanFangDetailItem
from ArtIntelligenceCompany.pipelines import GetWanFangDetailPipeline
import time
import os
class GetwanfangdetailSpider(scrapy.Spider):
name = 'GetWanFangDetail'
allowed_domains = ['lib-wf.sstir.cn']
base_url = 'http://lib-wf.sstir.cn'
start_urls = [base_url]
custom_settings = {
'ITEM_PIPELINES':{'ArtIntelligenceCompany.pipelines.GetWanFangDetailPipeline': 300}
}
#没有找到的页
notFindPage=[]
#当前爬取的第几页
pageNum=1
#最大尝试次数
MaxTryNum=10
#已经尝试了几次
triedNum=0
#要搜索的论文列表
articleList = []
#要搜索第几篇论文
articleRank=0
#要检索的论文数
articleMaxNum=0
#当前被检索论文的id
currentArticleId=0
def __init__(self, *args, **kwargs):
super(GetwanfangdetailSpider, self).__init__(*args, **kwargs)
for oneArticle in GetWanFangDetailPipeline().getInitArticleList():
self.articleList.append(oneArticle)
self.articleMaxNum = len(self.articleList)
print("================total get article:%d==============" % self.articleMaxNum)
self.GetNextArticle()
def GetNextArticle(self):
self.start_urls[0] = self.base_url + self.articleList[self.articleRank][1]
self.currentArticleId = self.articleList[self.articleRank][0]
self.articleRank+=1
return
def parse(self, response):
item = GetWanFangDetailItem()
detailBlock = response.xpath('//div[@class="detail_div"]')
item["ID"] = self.currentArticleId
item["title"] = detailBlock.xpath('./h1').xpath('string(.)').extract()
item["shortInfo"] = detailBlock.xpath('./p[@class="abstracts"]').xpath('string(.)').extract()
detailBlock = detailBlock.xpath('./dl[@id="perildical2_dl"]')
item["author"] = detailBlock.xpath('./dd[1]').xpath('string(.)').extract()
item["specialty"] = detailBlock.xpath('./dd[2]').xpath('string(.)').extract()
item["degree"] = detailBlock.xpath('./dd[3]').xpath('string(.)').extract()
item["school"] = detailBlock.xpath('./dd[4]').xpath('string(.)').extract()
item["teacherName"] = detailBlock.xpath('./dd[5]').xpath('string(.)').extract()
item["grantTime"] = detailBlock.xpath('./dd[6]').xpath('string(.)').extract()
item["studyDirection"] = detailBlock.xpath('./dd[7]').xpath('string(.)').extract()
item["language"] = detailBlock.xpath('./dd[8]').xpath('string(.)').extract()
item["classification"] = detailBlock.xpath('./dd[9]').xpath('string(.)').extract()
item["keyword"] = detailBlock.xpath('./dd[10]').xpath('string(.)').extract()
item["classificationByMachine"] = detailBlock.xpath('./dd[11]').xpath('string(.)').extract()
item["keywordByMachine"] = detailBlock.xpath('./dd[12]').xpath('string(.)').extract()
item["fundProject"] = detailBlock.xpath('./dd[13]').xpath('string(.)').extract()
if len(item["title"])>0 :
self.triedNum=0
yield item
if self.articleRank<self.articleMaxNum:
self.GetNextArticle()
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
else:
if self.triedNum < self.MaxTryNum:
self.triedNum +=1
print("---------ID:%d Have tried %d Times-----------------------------" % (self.articleRank,self.triedNum))
time.sleep(self.triedNum*3)
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
else:
yield item
if self.articleRank<self.articleMaxNum:
self.notFindPage.append(self.currentArticleId)
self.GetNextArticle()
yield scrapy.Request(self.start_urls[0],callback=self.parse,dont_filter=True)
else:
print(self.notFindPage)
filepath=os.path.dirname(__file__)+r'/notFindArticle.txt'
print("调试文件位置:",filepath)
if os.path.exists(filepath):
os.remove(filepath)
with open(filepath, 'x' , encoding='utf-8') as fp:
fp.writelines(self.notFindPage)
print("==============search over!===============")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
← python爬虫1 python测试代码 →