# k8s基础入门
# 背景
Kubernetes是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes能够进行应用的自动化部署和扩缩容。在Kubernetes中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。它可以帮助:
- 从IT基础设施主机化向容器化转换
- 从人肉式运维工作模式向自动化运维模式转换
- 从自动化运维体系向全体系智能化运维模式转换
这里涉及到主机->虚拟机->容器过渡,为了降低虚拟机造成的物理主机资源浪费,提高物理主机的资源利用率,并能够提供像虚拟机一样良好的应用程序隔离运行环境,人们把这种轻量级的虚拟机,称为"容器"。
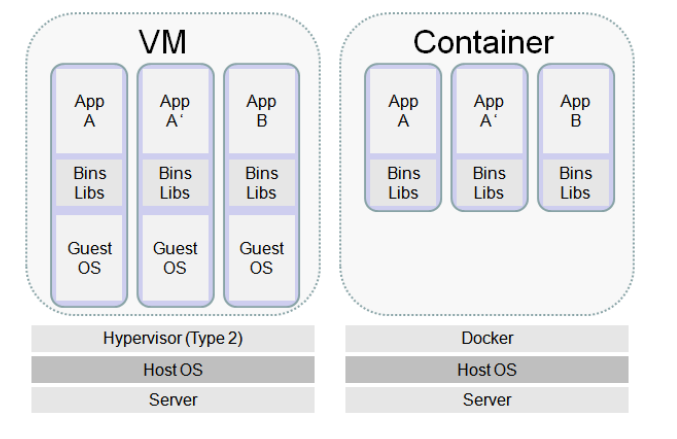
# 容器管理工具
容器管理工具类似于虚拟机管理工具,主要用于容器的创建、启动、关闭、删除等。常用的管理工具有:
- docker公司的 docker
- 国内阿里公司的 Pouch
- LXC、LXD、RKT等等
# 容器编排部署工具
容器管理工具可以完成容器的基础管理,但是容器的应用并不是只能进行简单应用部署的,可以使用容器完成企业中更加复杂的应用部署,当需要对多应用的系统进行部署时,就需要更加复杂的工具来完成对容器运行应用的编排,这就是我们所说的容器编排部署工具。常见的容器编排部署工具有:
- docker三剑客:
- docker machine:在远程电脑上安装Docker引擎。
- docker compose:定义和运行多容器应用。
- docker swarm:原生集群工具。
- mesos + marathon:
- mesos的主要作用是在分布式计算过程中,对计算机资源进行管理和分配。
- Marathon实现了服务发现和负载平衡、为部署提供REST API服务、授权和SSL、配置约束等功能。Marathon支持通过Shell命令和Docker部署应用。提供Web界面、支持cpu/mem、实例数等参数设置,支持单应用的Scale,但不支持复杂的集群定义。
- 如果将Mesos类比为操作系统的内核,负责资源调度。则Marathon可以类比为服务管理系统,比如init,systemd或upstart等系统,用来管理应用的状态信息。Marathon将应用程序部署为长时间运行的Mesos任务。
- kubernetes:主要用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效,提供了应用部署,规划,更新,维护的一种机制。
# 起源
k8s起源于谷歌的Borg系统开源,归属于CNCF (opens new window),它是一个开源软件基金会,致力于云计算的普遍性和持续性。OpenShift和Rancher的平台核心是k8s,它的主要贡献者为Google,Redhat,Microsoft,IBM,Intel。它的版本历史:
- 2014年9月:第一个正式版本。
- 2015年7月:1.0版本。
- 2017年10月:docker支持kubernetes。
早期Kubernetes的Node数也就100台,pod管理支持就1000个,到2021年OpenAI将Node数扩展到了7500个,Pod数超过150000个。
# K8s功能
- 自动装箱:基于容器对应用运行环境的资源配置要求自动部署应用容器
- 自我修复(自愈能力):
- 当容器失败时,会对容器进行重启。
- 当所部署的Node节点有问题时,会对容器进行重新部署和重新调度。
- 当容器未通过监控检查时,会关闭此容器。
- 直到容器正常运行时,才会对外提供服务。
- 水平扩展:通过简单的命令、用户UI界面或基于CPU等资源使用情况,对应用容器进行规模扩大或规模剪裁。
- 服务发现:用户不需要使用额外的服务发现机制,就能够基于Kubernetes自身能力实现服务发现和负载均衡。
- 滚动更新:可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新。
- 版本回退:可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退。
- 密钥和配置管理:在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
- 存储编排:
- 自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要。
- 存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph、Cinder等)、公共云存储服务等。
# K8s架构
目前主要有两类集群架构:
- 无中心节点架构:
- GlusterFS
- 有中心节点架构:
- HDFS
- K8S
那么K8S的集群架构节点角色功能:
- MasterNode
- k8s集群控制节点,对集群进行调度管理,接受集群外用户去集群操作请求;
- Master Node由API Server、Scheduler、Cluster State Store(ETCD数据库)和Controller Manger Server所组成;
- WorkerNode
- 集群工作节点,运行用户业务应用容器;
- Worker Node包含kubelet、kube proxy和Container Runtime;
他们架构图如下:
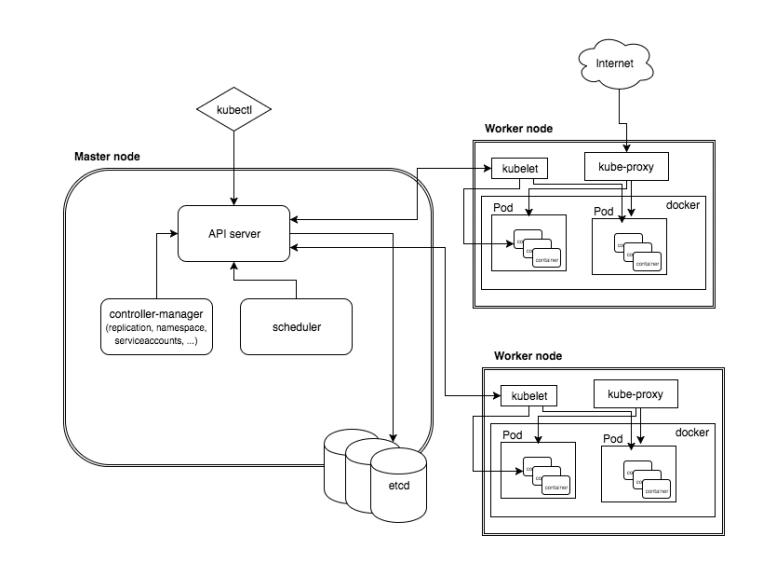

下面介绍下他们的组件:
- kubectl:管理K8s的命令行工具,可以操作K8s中的资源对象。
- etcd:是一个高可用的键值数据库,存储K8s的资源状态信息和网络信息的,etcd中的数据变更是通过api server进行的。
- apiserver: 提供K8s api,是整个系统的对外接口,提供资源操作的唯一入口,供客户端和其它组件调用,提供了K8s各类资源对象(pod,deployment,Service等)的增删改查,是整个系统的数据总线和数据中心,并提供认证、授权、访问控制、API注册和发现等机制,并将操作对象持久化到etcd中。相当于“营业厅”。
- scheduler:负责K8s集群中pod的调度的,scheduler通过与apiserver交互监听到创建Pod副本的信息后,它会检索所有符合该Pod要求的工作节点列表,开始执行Pod调度逻辑。调度成功后将Pod绑定到目标节点上,相当于“调度室”。
- controller-manager:与apiserver交互,实时监控和维护K8s集群的控制器的健康情况,对有故障的进行处理和恢复,相当于“大总管”。
- kubelet:每个Node节点上的kubelet定期就会调用API Server的REST接口报告自身状态,API Server接收这些信息后,将节点状态信息更新到etcd中。kubelet也通过API Server监听Pod信息,从而对Node机器上的POD进行管理,如创建、删除、更新Pod。
- kube-proxy:提供网络代理和负载均衡,是实现service的通信与负载均衡机制的重要组件,kube-proxy负责为Pod创建代理服务,从apiserver获取所有service信息,并根据service信息创建代理服务,实现service到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络,将到service的请求转发到后端的pod上。
# 部署安装
主要有两种方式部署。
# 二进制源码包部署
- 获取源码包
- 部署在各节点中
- 启动服务
- Master
- api-server
- etcd
- scheduler
- controller manager
- Worker
- kubelet
- kube-proxy
- docker
- Master
- 生成证书
- http
- https
# 使用kubeadmin部署
参考资料:
主要安装部署如下:
- 安装软件 kubelet kubeadm kubectl
- 初始化集群
- 添加node到集群中
- 证书自动生成
- 集群管理系统是以容器方式存在,容器运行在master
- 容器镜像是谷歌提供
- 阿里云下载容器镜像,需要重新打标记
- 谷歌下载
前置条件:
- 需要三台至少2CPU 2G内存的linux服务器。他们之间网络互通。
- 每台服务器要有独立的主机名,MAC地址和product_uuid。
- 每台服务器要禁用Swap,firewalld,以及SELINUX。
- 三台主机之间要时间同步。
修改主机名为唯一的:
查看主机名:
hostname
设置主机名:
hostnamectl set-hostname master1
hostnamectl set-hostname worker1
hostnamectl set-hostname worker2如果可以的话设置ip地址。
设置主机机名称解析。修改/etc/hosts文件:
192.168.20.20 master1 192.168.20.21 worker1 192.168.20.22 worker21
2
3
查看MAC是否是唯一的:
ip link
ifconfig -a查看product_uuid是否唯一,正常情况下这个均为唯一:
cat /sys/class/dmi/id/product_uuid
如果不唯一,则需要修改,下面是Hyper-V虚拟平台的修改方案:
$VMName = '<NameOfVirtualMachine>' $MSVM = Get-WmiObject -Namespace root\virtualization\v2 -ClassName Msvm_ComputerSystem -Filter "ElementName = '$VMName'" # get current settings object $MSVMSystemSettings = $null foreach($SettingsObject in $MSVM.GetRelated('Msvm_VirtualSystemSettingData')) { $MSVMSystemSettings = [System.Management.ManagementObject]$SettingsObject } # assign a new id $MSVMSystemSettings['BIOSGUID'] = "{$(([System.Guid]::NewGuid()).Guid.ToUpper())}" $VMMS = gwmi -Namespace root\virtualization\v2 -Class msvm_virtualsystemmanagementservice # prepare and assign parameters $ModifySystemSettingsParameters = $VMMS.GetMethodParameters('ModifySystemSettings') $ModifySystemSettingsParameters['SystemSettings'] = $MSVMSystemSettings.GetText([System.Management.TextFormat]::CimDtd20) # invoke modification $VMMS.InvokeMethod('ModifySystemSettings', $ModifySystemSettingsParameters, $null)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19关闭firewalld。
systemctl stop firewalld systemctl disable firewalld firewall-cmd --state1
2
3ubuntu下是ufw:
ufw disable1关闭SELinux
sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
关闭Swap分区
systemctl --type swap systemctl mask "dev-sda3.swap"
或者是在/etc/fstab中关掉。
临时关闭:
swapoff -a
验证是否已经关掉:
free -m
lsblk -o +PARTTYPE时间同步
apt install ntpdate
crontab -e
0 */1 * * * ntpdate time1.aliyun.com
crontab -l配置网桥过滤,以及转发。将 Linux 系统作为路由或者 VPN 服务就必须要开启 IP 转发功能。当 linux 主机有多个网卡时一个网卡收到的信息是否能够传递给其他的网卡。如果设置成 1 的话可以进行数据包转发,可以实现 VxLAN 等功能。不开启会导致 docker 部署应用无法访问。
vi /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 # 开启主机向容器的包转发 net.ipv4.ip_forward = 1 vm.swappiness = 01
2
3
4
5modprobe br_netfilter
modprobe overlay lsmod | grep br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf或者使用下面方式配置永久生效:
cat <<EOF | tee /etc/modules-load.d/k8s.conf br_netfilter EOF1
2
3开启ipvs:
apt install ipset ipvsadm mkdir -p /etc/sysconfig/modules/1
2添加需要加载的模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack EOF1
2
3
4
5
6
7
8授权运行:
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules1检查是否开启:
lsmod | grep -e ip_vs -e nf_conntrack_ipv41安装docker,并配置cgroupdriver(/etc/docker/daemon.json)。
{ "exec-opts":["native.cgroupdriver=systemd"] }1
2
3使用如下命令查看:
# 查看所有可安装docker的版本: apt-cache madison docker.io # 查看docker相关信息 docker info1
2
3
4修改k8s的cgroup配置。在1.22以后如果用户不设置,kubeadmin默认设置为systemd。这一步应该不用设置。
#k8s默认配置文件为 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf vi /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--cgroup-driver=systemd" # 或者debian如下: cat > /etc/default/kubelet <<EOF KUBELET_EXTRA_ARGS=--cgroup-driver=systemd --fail-swap-on=false EOF # 可以用下面的命令查看是否有上面设置的参数。 systemctl status -l kubelet systemctl daemon-reload systemctl enable kubelet systemctl restart kubelet1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# kubeadm安装
首先要知道k8s的三大组件:
- kubeadm:初始化集群、管理集群。
- kubelet:用于接收api server指令,对pod生命周期进行管理。
- kubectl:集群命令行管理工具。
在这我们主要使用kubeadm。它在k8s生态中的位置如下:
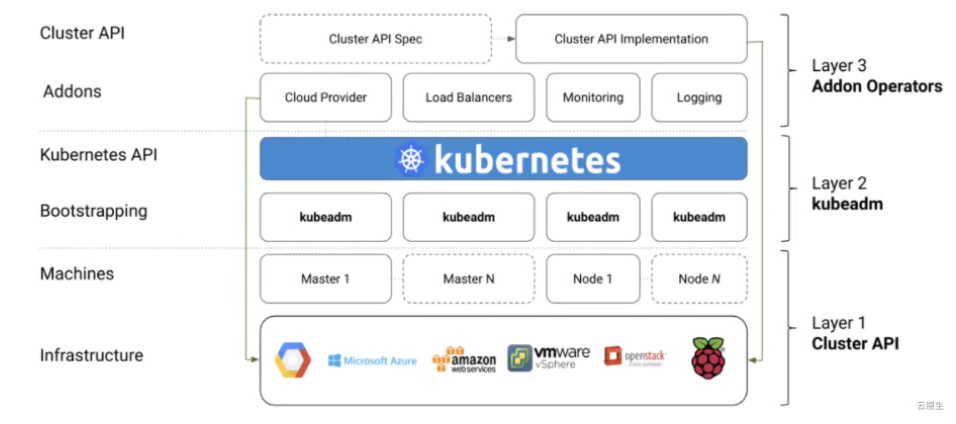
常用命令如下:
# 启动一个 Kubernetes 主节点
kubeadm init
# 启动一个 Kubernetes 工作节点并且将其加入到集群
kubeadm join
# 更新一个 Kubernetes 集群到新版本
kubeadm upgrade
# 如果你使用 kubeadm v1.7.x 或者更低版本,你需要对你的集群做一些配置以便使用 kubeadm upgrade 命令
kubeadm config
# 查看管理令牌
kubeadm token
# 还原之前使用 kubeadm init 或者 kubeadm join 对节点产生的改变,删除之前的操作。
kubeadm reset
# 打印出 kubeadm 版本
kubeadm version
# 预览一组可用的新功能以便从社区搜集反馈
kubeadm alpha
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
注意如果是国内的话需要使用国内的镜像源
apt-get update && apt-get install -y apt-transport-https
curl -fsSL https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
cat >/etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
# 删除旧的版本
apt remove kubeadm kubectl kubelet -y
# 安装最新版本
apt -y install kubectl kubelet kubeadm
# 升级系统时不升级这些组件
apt-mark hold kubelet kubeadm kubectl
# 安装指定版本
apt install -y kubelet=1.23.2-00 kubeadm=1.23.2-00 kubectl=1.23.2-00
# 查看版本
kubectl version
# 开机启动
systemctl enable kubelet
# 查看出错信息
journalctl -xefu kubelet
# -xefu 说明
# -x --catalog Add message explanations where available
# -e --pager-end Immediately jump to the end in the pager
# -f --follow Follow the journal
# -u --unit=UNIT Show logs from the specified unit
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
如果是其他节点下载缓慢可以同步Master节点的:
如果集群下载缓慢的话,需要同步apt缓存,位置在/var/cache/apt/archives/
rsync -av --progress /var/cache/apt/archives/ root@master1:/var/cache/apt/archives/
2
3
# K8S和Docker
# CRI接口时间演变
参考文档:
- Docker,containerd,CRI,CRI-O,OCI,runc 分不清? (opens new window)
- K8s为什么要弃用 Dockershim? (opens new window)
K8S和Docker的关系有些复杂,基本他们之间的演进关系如下:
- 2014年Docker是鼎盛时期,K8S刚诞生,当时它支持Docker。
- 2015年7月,K8S发布1.0版本。
- 2015年12月11日,CNCF成立。
- 2016年12月9日,K8S的1.5版本发布,引入了CRI(Container Runtime Interface)容器运行时接口。在此之前Kubelet通过内嵌的dockershim操作Docker API。
- 2016年12月,docker在容器生态中竞争失败,宣布将其containerd捐赠给CNCF。2017年3月containerd正式加入CNCF。
- 2017年10月,CRI-O的1.0发布,支持将runc和Kata容器作为容器运行时。CRI-O 能够让 Kubernetes 使用任意兼容 OCI 的运行时作为运行 Pod 的容器运行时,CRI-O 本身也是 CRI-runtime。操控 CRI-O 的常用命令行工具包括:
- crictl:用于排除故障和直接与 CRI-O 容器引擎一起工作(需安装 cri-tools,较常用)。
- runc:用于运行容器镜像(CRI-O 自带,几乎不用)。
- podman:用于在容器引擎之外管理 pod 和容器镜像(run, stop, start, ps, attach, exec 等,需安装 podman,经常用)。一些 Docker 功能被包含在其他工具中,而不是 CRI-O 中。例如,podman提供了与许多 docker 命令功能完全兼容的命令行,并将这些功能也扩展到管理 pod 上。一些 Docker 功能被包含在其他工具中,而不是 CRI-O 中。例如,podman提供了与许多 docker 命令功能完全兼容的命令行,并将这些功能也扩展到管理 pod 上。
- 2018年7月发布Containerd1.1.2正式将CRI-containerd以插件形式cri-plugion集成到了Containerd中。理论上来说,从此刻开始Containerd就可以独立支持Kubelete CRI了。
# CRI接口架构演变
看下containerd和dockershim之间的:
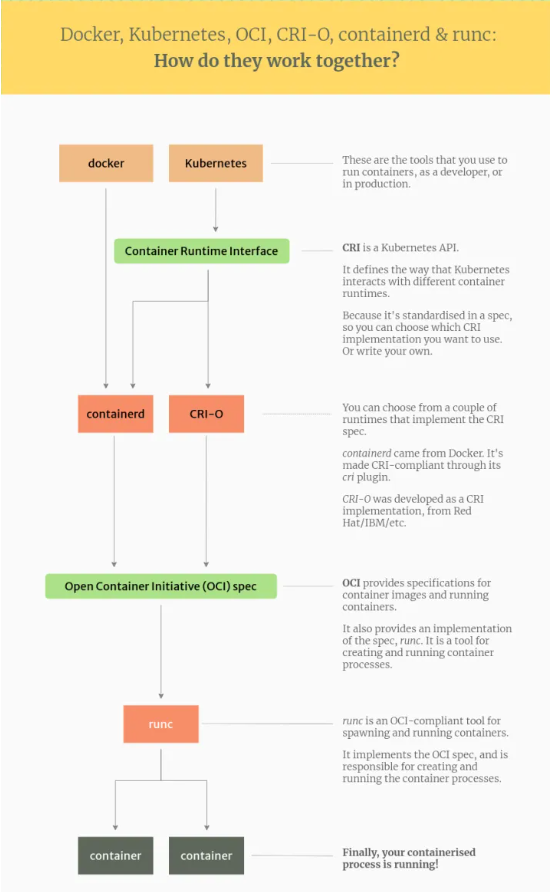
使用docker-shim的时候:
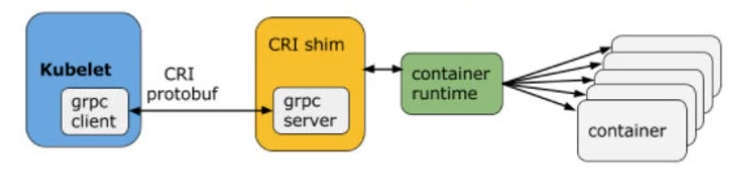
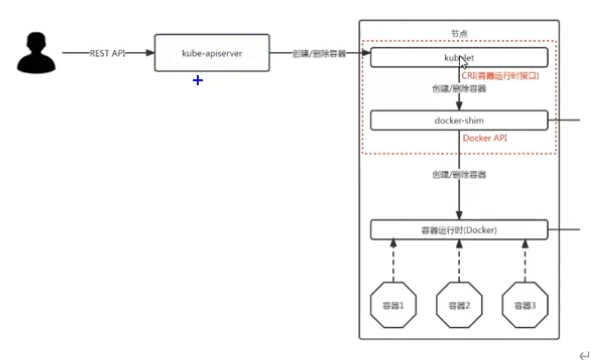

到了Containerd时候:
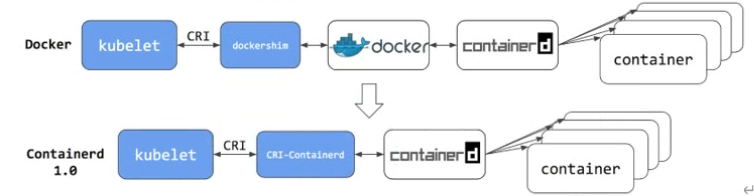
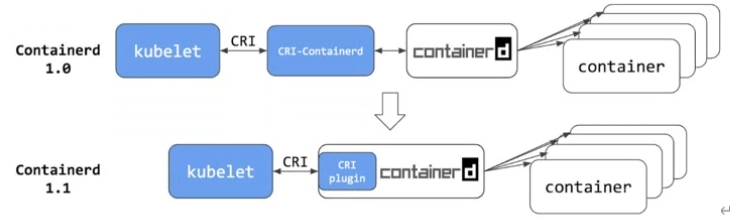
在k8s的1.24版本以后,Dockershim不在kubelet里面了,这个时候的选择有:
- 安装docker-ce,containerd,以及dockershim(cri-dockerd)。
- 安装containerd。
- 安装cri-o。
# Cri-Dockerd
dpkg -i download.deb。
systemctl start cri-docker.service cri-docker.socket
配置cri-dockerd
vim /usr/lib/systemd/system/cri-docker.service ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause # 注意 sock 是/var/lib/cri-dockerd.sock # 启动服务 systemctl daemon-reload systemctl restart cri-docker.service cri-docker.socket #设置开机启动 systemctl enable cri-docker.service cri-docker.socket # 查看启动状态 systemctl status cri-docker.service cri-docker.socket # 卸载 dpkg -P cri-dockerd1
2
3
4
5
6
7
8
9
10
11
12
13配置kubelet:
# 配置kubelet vi /var/lib/kubelet/kubeadm-flags.env KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause" # 重启kubelet systemctl daemon-reload systemctl restart kubelet1
2
3
4
5
6
7
8启动Master节点:
# 下载相关镜像 kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --cri-socket unix:///var/run/cri-dockerd.sock # kubeadm初始化 # --kubernetes-version=v1.26.0 # --apiserver-advertise-address 为本机ip。 kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.10.0.0/16 --service-cidr=10.20.0.0/16 --apiserver-advertise-address=192.168.20.20 --cri-socket unix:///var/run/cri-dockerd.sock1
2
3
4
5
6
7
# 使用containerd方式
下面是直接把worker1节点从cri-dockerd变为containerd方式。如果是一开始就使用containerd方式,只用第5,6步就行了。
先查看下有多少pod在该节点上:
kubectl get pod -owide -A | grep worker1 kubectl get pod -owide -A -w kubectl describe node worker11
2
3将该节点设置为不可调度,并驱离
kubectl drain worker1 --ignore-daemonsets
停掉cri-dockerd
systemctl stop docker docker.socket systemctl disable docker docker.socket systemctl stop cri-docker.service cri-docker.socket systemctl disable cri-docker.service cri-docker.socket1
2
3
4启动containerd:
systemctl status containerd.service1修改containerd的配置文件:
containerd config default > /etc/containerd/config.toml vi /etc/containerd/config.toml # 做如下操作: [plugins."io.containerd.grpc.v1.cri"] sandbox_image = "registry.aliyuncs.com/google_containers/pause" [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true [plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] endpoint = ["https://b9pmyelo.mirror.aliyuncs.com"] # 重启containerd systemctl daemon-reload systemctl restart containerd.service1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16配置kubelet使用containerd:
vi /var/lib/kubelet/kubeadm-flags.env KUBELET_KUBEADM_ARGS="--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause" systemctl daemon-reload systemctl restart kubelet kubectl get nodes -o wide1
2
3
4
5
6
7
8把当前节点设置为可调度的:
# cordon是设置为不可调度,不驱离。 kubectl uncordon worker1 # 删掉master上的一节点发现会到worker1上 kubectl delete pod podName crictl ps crictl pods1
2
3
4
5
6
# CRI-O方式安装
启用内核模块:
modprobe overlay modprobe br_netfilter1
2安装cri-o,设置好下面环境变量然后按照文档 (opens new window)安装:
export VERSION=1.26 export OS=Debian_111
2配置镜像地址,启动cri-o
vi /etc/crio/crio.conf pause_image = "registry.aliyuncs.com/google_containers/pause" systemctl daemon-reload systemctl restart crio systemctl enable crio1
2
3
4
5
6配置kubelet
vi /var/lib/kubelet/kubeadm-flags.env KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=unix:///var/run/crio/crio.sock --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause" systemctl daemon-reload systemctl restart kubelet systemctl enable kubelet1
2
3
4
5
6加入Master节点
kubeadm token create --print-join-command kubeadm join MasterIp:6443 --token ywalg8.biu9f8whl3n59q7l --discovery-token-ca-cert-hash sha256:aff733afd431754a2a0f978be5a4261b3d17c0af5abbf2cf0fd2dfe655e3996e --cri-socket unix:///var/run/crio/crio.sock scp root@master1:/root/.kube/config /root/.kube/config kubectl label nodes worker2 node-role.kubernetes.io/node= # 也可不用做如下操作 crictl config --set runtime-endpoint=unix:///var/run/crio/crio.sock # 做个测试 kubectl scale deployment demo1 --replicas 8 # 查看不同的实例所在节点 kubectl get pod -owide1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Master节点配置
使用kubeadm启动:
# 下载相关镜像
kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --cri-socket unix:///var/run/cri-dockerd.sock
# kubeadm初始化
# --kubernetes-version=v1.26.0
# --apiserver-advertise-address 为本机ip。
kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.10.0.0/16 --service-cidr=10.20.0.0/16 --apiserver-advertise-address=192.168.20.20 --cri-socket unix:///var/run/cri-dockerd.sock
2
3
4
5
6
7
注意--cri-socket的可能性一共有以下四种:
- unix:///var/run/dockershim.sock #1.24.0 以后版本已经没有了
- unix:///run/containerd/containerd.sock #没有docker,有 containerd
- unix:///run/crio/crio.sock #没有containerd和docker
- unix:///var/run/cri-dockerd.sock #有cri-docker + docker + containerd
# 安装flannel网络
上面安装完后,配置以使kubectl访问集群
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config # 使用如下命令查看是否有coredns,如果没有需要进行第2步卸载重新装,如果有的话直接第3步。 kubectl get pod -A1
2
3
4
5卸载kubelet
kubeadm reset kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock # 清空定义的所有内容 # 使用 flannel 插件 ip link delete cni0 ip link delete flannel.1 rm -rf /var/lib/cni/ rm -rf /etc/kubernetes rm -rf /root/.kube/config rm -rf /var/lib/etcd ipvsadm -C1
2
3
4
5
6
7
8
9
10
11安装pod Flannel网络,需要下载文件kube-flannel.yml (opens new window):
将其中PodCIDR默认地址从"10.244.0.0/16"改为"10.10.0.0/16"
如果有多个网卡,使用如下参数指定
- --ip-masq - --kube-subnet-mgr - --iface=enp0s81
2
3kubectl apply -f kube-flannel.yaml
kubectl get ds -l app=flannel -n kube-system
kubectl get pod -A # 正常情况下应该会有flannel的相关容器
# 去掉调度污点
上面安装完后,可以测试部署应用了:
kubectl create deployment demo1 --image=nginx:latest
kubectl delete pods podsName
kubectl delete deployment demo1
kubectl get pod
kubectl describe pod podName
上面操作或显示状态为pending,这是因为当前master节点角色为控制平面,是不允许运行容器的。它有一个不能调度的污点标志,如果我们想让master节点运行容器,需要去掉这个污点。
kubectl describe node | grep -i taint
kubectl taint nodes master1 node-role.kubernetes.io/master- #1.24.0以前
kubectl taint node master1 node-role.kubernetes.io/control-plane- # 1.24.0以后
# 使用ipvs转发流量
让k8s的负载均衡使用ipvs来转发流量:
kubectl describe configmap kube-proxy -n kube-system
kubectl edit configmap kube-proxy -n kube-system
mode: "ipvs"
kubectl get pod -A
# 删掉后会发现它会重启一个
kubectl delete pod -n kube-system kube-proxy-*
2
3
4
5
6
7
8
# 从节点配置
如果当前环境是从Master节点镜像过来的,需要:
- 修改ip
- 删除k8s
- 修改主机名
在Master节点上:
kubeadm token create --print-join-command
在从节点上:
kubeadm join MasterIp:6443 --token ywalg8.biu9f8whl3n59q7l --discovery-token-ca-cert-hash sha256:aff733afd431754a2a0f978be5a4261b3d17c0af5abbf2cf0fd2dfe655e3996e --cri-socket unix:///var/run/cri-dockerd.sock
然后准备kubectl
mkdir .kube
scp root@master1:/root/.kube/config /root/.kube/config
2
检查角色:
kubectl get node
kubectl label nodes worker1 node-role.kubernetes.io/node=
2
扩充负载:
kubectl scale deployment demo1 --replicas 5
# 查看不同的实例所在节点
kubectl get pod -owide
2
3
4
# 其他
# 设置别名
vi /etc/profile
alias k=kubectl
complete -F __start_kubectl k
2
3
# 常见错误诊断
当出现错误时,可以依次查看如下是否跟我们配置的一样:
systemctl status -l kubelet
systemctl status -l cri-docker
systemctl status cri-docker.socket
journalctl -xefu kubelet
# k8s查看组件状态
kubectl get cs
# 查看pod,留意下coredns是否安装
kubectl get pod -A
# 查看节点
kubectl get node -owide
kubectl get all -A
2
3
4
5
6
7
8
9
10
11
# 常见错误
如果出现如下错误:
unknown service runtime.v1alpha2.RuntimeService1解决办法:将 /etc/containerd/config.toml中的disabled_plugins = ["cri"]注释掉。
如果kubelet安装失败,可能是cri-docker配置未生效。
出现错误:
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.1这时可以需要设置crictl使用哪个socket
crictl config runtime-endpoint unix:///var/run/containerd/containerd.sock1也可以修改默认配置文件:
vi /etc/crictl.yaml # 加入如下编辑内容 runtime-endpoint: unix:///var/run/containerd/containerd.sock image-endpoint: unix:///var/run/containerd/containerd.sock debug: false pull-image-on-create: false disable-pull-on-run: false1
2
3
4
5
6
7
# cgroup介绍
cgroups,其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。它的一个设计目标是为不同的应用情况提供统一的接口,从控制单一进程(像nice)到操作系统层虚拟化(像OpenVZ,Linux-VServer,LXC)。cgroups提供:
- 资源限制:组可以被设置不超过设定的内存限制;这也包括虚拟内存。
- 优先级:一些组可能会得到大量的CPU或磁盘IO吞吐量。
- 结算:用来衡量系统确实把多少资源用到适合的目的上。
- 控制:冻结组或检查点和重启动。
具体功能如下:
- 限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会触发OOM(out of memory)。
- 进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
- 记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间。
- 进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
- 进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
cgroup 是通过一系列的文件来管控所有的资源分配的,包括创建了一个 cgroup,同时将一个 cgroup 和这个进程进行关联,也就是将进程号 echo 到那个 procs 文件里面,同时修改cpu 的 quota 来限制其使用的资源,这一整套都是 cgroup 的文件系统,cgroup 本身可以有不同的 driver。
docker 默认用 cgroupfs 作为 cgroup 驱动。而操作系统默认使用systemd驱动(systemd cgroup driver),如果其他进程是使用 systemd 拉起来的,systemd 拉起来的那些进程就由 systemd 这套系统去管控的,docker 拉起的进程是由 cgroupfs 这套系统去管控的,这就会出现同一套资源被两套系统网外分,当系统压力大的时候就会引发不必要的问题,所以kubernetes 在启动的时候会做一些检查,在启动 kubelet 的时候,去判断 docker 使用了哪一个 cgroup driver,如果 docker 本身不是使用 systemd,那么它就会默认报错不启动。所以当使用 kubernetes 的时候,要将两者统一。
当操作系统使用 systemd 作为 init system 时,初始化进程生成一个根 cgroup 目录结构并作为 cgroup 管理器。systemd 与 cgroup 紧密结合,并且为每个 systemd unit 分配 cgroup,因此,在 systemd 作为 init system 的系统中,默认并存着两套 groupdriver。docker 和 kubelet 管理的进程被 cgroupfs 驱动管理,而 systemd 拉起的服务由 systemd 驱动管理,让 cgroup 管理混乱且容易在资源紧张时引发问题。因此 kubelet 会默认--cgroup-driver=systemd,若运行时 cgroup 不一致时,kubelet 会报错。
# 下载镜像
保存相关镜像:
kubeadm config images list >> image.list
下载相关镜像:
#!/bin/bash
img_list='
k8s.gcr.io/kube-apiserver:v1.17.2
k8s.gcr.io/kube-controller-manager:v1.17.2
k8s.gcr.io/kube-scheduler:v1.17.2
k8s.gcr.io/kube-proxy:v1.17.2
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.5
'
for img in $img_list
do
docker pull $img
done
2
3
4
5
6
7
8
9
10
11
12
13
14
15
worker节点需要的镜像为:
k8s.gcr.io/kube-proxy
k8s.gcr.io/pause