# Java类集框架
类集是Java针对常用数据结构的官方实现,因此需要了解它们的实现以及应用场景,JDK 1.5之后为了让类集更加安全,加入了泛型操作。
Java中传统的数组能保存多个数据,但是有长度的使用限制,因为长度问题,开始使用数据结构来实现动态数组处理,如果开发者自己开发的话会有下面的问题:
- 但是数据结构代码实现困难
- 需要对这些代码不断的优化更新
- 需要考虑到多线程并发处理
- 难以成为行业认可的标准
为了解决这些问题,从JDK 1.2开始引入类集开发框架,但是这些都采用Object类型实现数据接收,会导致ClassCastException安全隐患。从JDK 1.5之后,由于泛型的推广,类集结构也得到了改进,直接利用泛型来统一类集存储数据的数据类型,从JDK 1.8开始对各种算法进行优化,提高性能。
类集为了提供标准的数据结构,提供了若干个核心接口,分别是Collection,List,Set,Map,Iterator,Enumeration,Queue,ListIterator。
# Collection集合
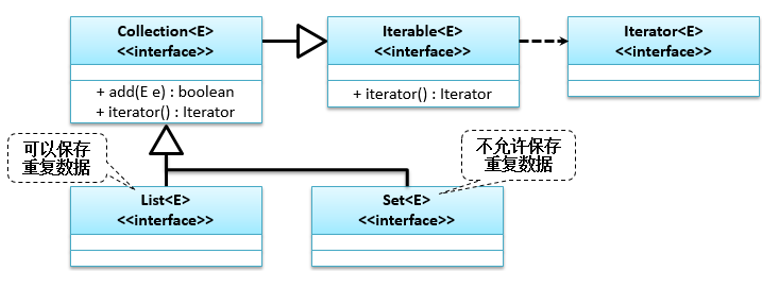
java.util.Collection是单值集合操作的最大的父接口,JDK 1.5之前Collection只是一个独立接口,JDK 1.5之后提供了Iterable父接口,JDK 1.8之后对Iterable接口进行了扩充,JDK 1.5之前一般直接操作Collection接口,JDK 1.5之后更多的是操作List和Set接口。其类继承关系如下:
# List
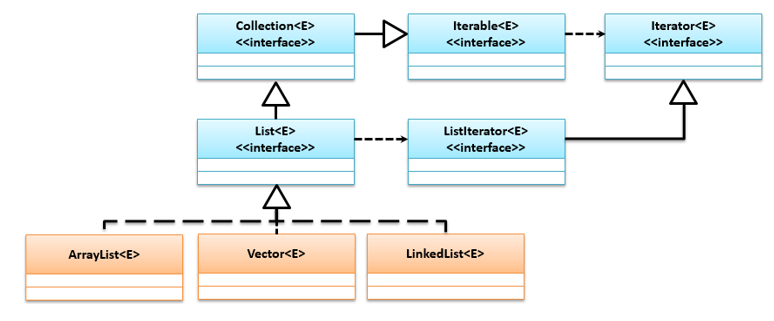
其为Collection子接口,它允许保存重复元素数据,实现该接口的常用子类有:ArrayList,Vector,LinkedList,它们的继承关系如下:
从JDK 1.9 List接口提供了of()静态方法,使用此方法可方便的将其他数据转换为List集合保存。
import com.sun.tools.javac.util.List;
public class Main {
public static void main(String[] args) {
List<String> listStr = List.of("hello","world","this","is","a","game");
//转换为数组
Object result[] = listStr.toArray();
for(Object one:result) {
System.out.print(one+",");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# ArrayList
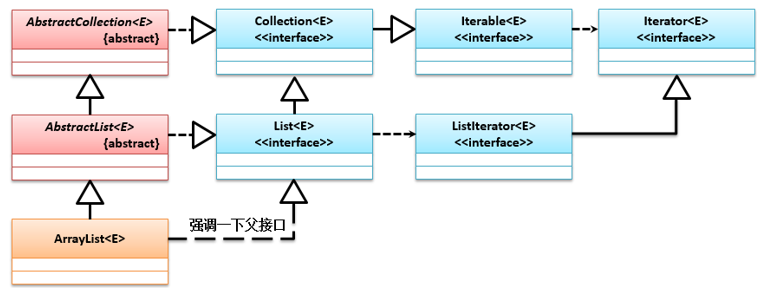
该类实现了List接口,又同时继承了AbstractList抽象类。该集合允许重复数据,其中存储数据的顺序是按添加时的顺序,它的继承结构如下:
import java.util.ArrayList;
import java.util.List;
class Person{
String nameString;
int ageInt;
public Person(String n,int a) {
nameString = n;
ageInt = a;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
Person temPerson = (Person)obj;
if(nameString == temPerson.nameString) {
return true;
}
return false;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "name:"+nameString+",age:"+ageInt;
}
}
public class Main {
public static void main(String[] args) {
List<String> arrList = new ArrayList<>();
arrList.add("hello");
arrList.add("world!");
arrList.add("this");
arrList.forEach((str)->{
System.out.println(str+",");
});
arrList.remove("this");
System.out.println(arrList);
System.out.println("是否空:"+arrList.isEmpty()+",集合元素个数:"+arrList.size());
System.out.println("第一个元素:"+arrList.get(1));
System.out.println();
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("li", 18));
personList.add(new Person("wang", 30));
personList.add(new Person("zhang", 20));
personList.add(new Person("song", 25));
System.out.println(personList.contains(new Person("zhang", 20)));
personList.remove(new Person("wang", 30));
personList.forEach(System.out::println);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# LinkedList
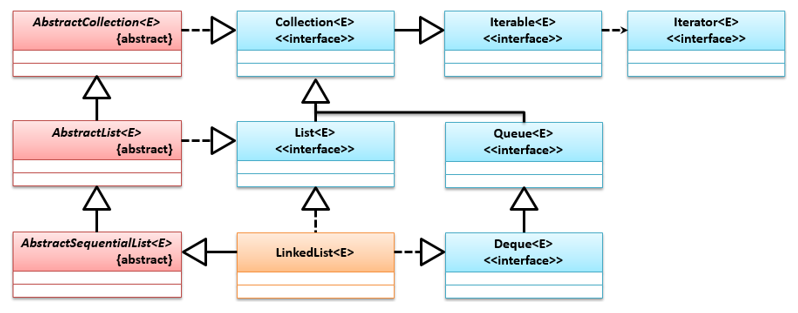
LinkedList是基于链表数据结构实现的List集合标准,该类除了实现List接口外,还实现了Deque接口,它们的继承关系如下:
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> linkedList = new LinkedList<String>();
linkedList.add("hello");
linkedList.add("world");
linkedList.add("this");
linkedList.add("is");
linkedList.add("sad");
linkedList.forEach(System.out::println);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Vector
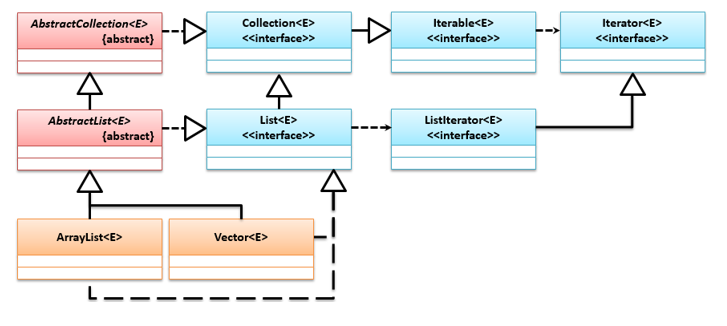
Vector是一个原始类,是在JDK 1.0时提供的,到了JDK 1.2的时候因为很多系统类基于它,便保留下来了,多实现了一个List接口。注意Vector和ArrayList都是AbstractList抽象类的子类,都实现了List接口,但是Vector都采用synchronized同步处理,是线程安全的,它的性能要比ArrayList差点。它们的类继承关系如下:
import java.util.List;
import java.util.Vector;
public class Main {
public static void main(String[] args) {
List<String> vectorList = new Vector<String>();
vectorList.add("hello");
vectorList.add("world");
vectorList.add("this");
vectorList.add("is");
vectorList.add("sad");
vectorList.forEach(System.out::println);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Set
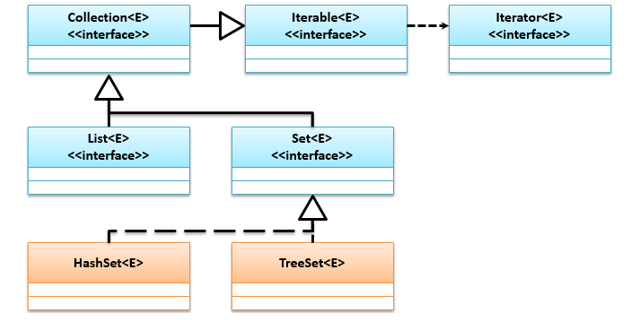
与List接口不同,Set接口要求内部不允许保存重复元素,JDK 1.9之前Set接口并没有对Collection接口功能进行扩充,之后才添加很多方法,提供了将多个对象转化为Set的方法。它有两个常用子类:HashSet(散列存放)和TreeSet(有序存放),它们的继承关系如下:
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> mySet = Set.of("hello","world","this","is","good");
System.out.println(mySet);
}
}
2
3
4
5
6
7
8
# HashSet
HashSet不允许保存重复元素,所有内容采用散列(无序)的方式进行存储。该类继承了AbstractSet抽象类,同时实现了Set接口,类继承关系如下:

import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> myHashSet = new HashSet<String>();
myHashSet.add("hello");
myHashSet.add("world");
myHashSet.add("is");
myHashSet.add("is");
System.out.println(myHashSet);
Set<String> myLinkedHashSet = new LinkedHashSet<String>();
myLinkedHashSet.add("hello");
myLinkedHashSet.add("world");
myLinkedHashSet.add("is");
myLinkedHashSet.add("is");
System.out.println(myLinkedHashSet);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
HashSet使用限制较少,它的问题在于无序处理,为了解决这个问题,在JDK 1.4后又提供了LinkedHashSet子类。
# TreeSet
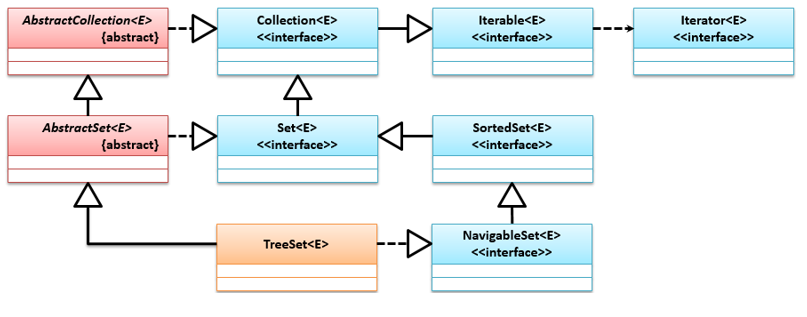
TreeSet可以排序保存,它继承了AbstractSet抽象类并实现了NavigableSet接口,它们的类继承关系如下:
import java.util.HashSet;
import java.util.Set;
import java.util.TreeSet;
class Person implements Comparable<Person>{
String nameString;
int ageInt;
static int count=0;
public Person(String n,int a) {
nameString = n;
ageInt = a;
}
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
//System.out.println("比较对象:"+o);
return this.ageInt-o.ageInt;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
System.out.println("hashCode:"+ageInt);
return ageInt;
//return count++;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
System.out.println("比较对象:"+obj);
if(this.toString().equals(obj.toString())) {
return true;
}
return false;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "name:"+nameString+",age:"+ageInt;
}
}
public class Main {
public static void main(String[] args) {
Set<String> myTreeSet = new TreeSet<String>();
myTreeSet.add("hello");
myTreeSet.add("world");
myTreeSet.add("is");
myTreeSet.add("is");
System.out.println(myTreeSet);
Set<Person> TreeSet2 = new TreeSet<Person>();
TreeSet2.add(new Person("li", 18));
TreeSet2.add(new Person("wang", 30));
TreeSet2.add(new Person("zhang", 20));
TreeSet2.add(new Person("song", 25));
TreeSet2.add(new Person("song2", 25));
TreeSet2.add(new Person("song", 32));
System.out.println("是否有 zhang2 20:"+TreeSet2.contains(new Person("zhang2", 20)));
TreeSet2.forEach((one)->{
System.out.println(one.equals(new Person("song", 25)));
});
System.out.println(TreeSet2);
Set<Person> hashSet = new HashSet<Person>();
hashSet.add(new Person("li", 18));
hashSet.add(new Person("zhang", 20));
hashSet.add(new Person("song", 25));
hashSet.add(new Person("song", 25));
hashSet.add(new Person("song2", 25));
System.out.println(hashSet);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
注意:
- TreeSet使用compareTo来比较两个对象是否相等。
- HashSet先比较hashCode,如果hashCode相等,则比较compareTo,如果该方法判断也相等,那么就认为这两个对象相等。
- hashCode只在内部机制以散列表实现的类中有用。会先被比较,如果不等就说明两个对象不等,如果相等就比较compareTo。
# 集合输出
Collection接口提供toArray()方法可将集合中的数据转为对象数组,然后再进行输出,但是这种效率比较低,类集框架提供了4种方式:Iterator,ListIterator,Enumeration,foreach。
# Iterator
它是专门的迭代输出接口,迭代是依次找每个元素,如果该元素有内容,则把内容取出。该接口依靠Iterable接口中的iterate()方法实例化。
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<String> setStrings = Set.of("hello","world","this","is","you!");
Iterator<String> iterator = setStrings.iterator();
while(iterator.hasNext()) {
String str = iterator.next();
if("you".equals(str)) {
//setStrings.remove(new String("you!"));
iterator.remove();
}else {
System.out.println(str+",");
}
}
System.out.println();
Set<String> hashSet = new HashSet<String>();
hashSet.add("hello");
hashSet.add("world");
hashSet.add("you");
Iterator<String> iter = hashSet.iterator();
while (iter.hasNext()) {
String str = iter.next();
if("you".equals(str)) {
//iter.remove();
hashSet.remove(new String("you"));
} else {
System.out.println(str+",");
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# ListIterator
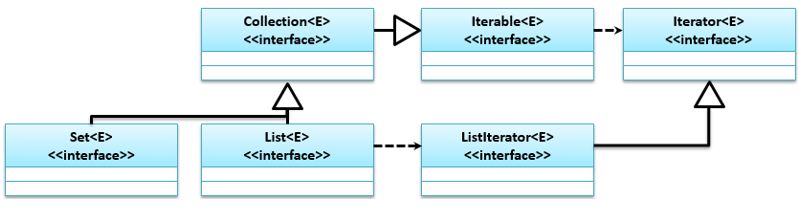
Iterator是由前往后单向输出,ListIterator可以由后往前。它的类继承关系如下:
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class Main {
public static void main(String[] args) {
List<String> listStr = new ArrayList<String>();
listStr.add("hello");
listStr.add("world");
listStr.add("this");
ListIterator<String> iter = listStr.listIterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
System.out.println();
while (iter.hasPrevious()) {
System.out.println(iter.previous());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Enumeration枚举
Enumeration是JDK 1.0推出的早期集合输出接口,主要用来输出Vector集合数据,在JDK 1.5后使用泛型对接口重新定义,它的类继承结构如下:

import java.util.Enumeration;
import java.util.Vector;
public class Main {
public static void main(String[] args) {
Vector<String> vectorStr = new Vector<String>();
vectorStr.add("hello");
vectorStr.add("world");
vectorStr.add("this");
Enumeration<String> enu = vectorStr.elements();
while(enu.hasMoreElements()) {
String str = enu.nextElement();
System.out.println(str+",");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# foreach输出
foreach除了可以实现数组输出外,也支持集合的输出操作。如果要自定义类也支持foreach,需要实现iterable接口,它是JDK 1.5之后提供的接口,注意Collection也继承了Iterable接口。
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
class MyInfo implements Iterable<String>{
private String[] contentStrings = {
"hello","world","you"
};
private int currentIndex=0;
class MyInfoIterator implements Iterator<String>{
@Override
public boolean hasNext() {
// TODO Auto-generated method stub
return currentIndex < contentStrings.length;
}
@Override
public String next() {
// TODO Auto-generated method stub
return contentStrings[currentIndex++];
}
}
@Override
public Iterator<String> iterator() {
// TODO Auto-generated method stub
return new MyInfoIterator();
}
}
public class Main {
public static void main(String[] args) {
Set<String> hashSet = new HashSet<String>();
hashSet.add("hello");
hashSet.add("world");
hashSet.add("you");
hashSet.forEach(System.out::println);
System.out.println();
MyInfo myInfo = new MyInfo();
myInfo.forEach(System.out::println);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# Map集合
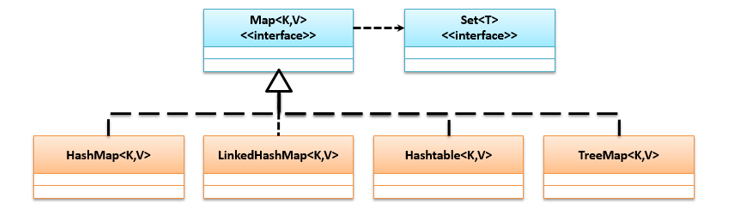
Map是存储键值对的标准接口,可以根据key获取value。从JDK 1.9之后,Map.of()方法可以把接收到的数据转换为Map,使用这种方法如果key重复或者为空值均会抛出异常。Map的常见的子类有HashMap、LinkedHashMap、Hashtable、TreeMap,它们的继承关系如下图:
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = Map.of("stu1",80,"stu2",90);
System.out.println(map);
}
}
2
3
4
5
6
7
8
# HashMap
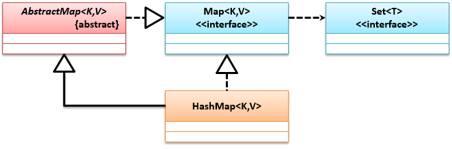
它采用散列方式存储,继承了AbstractMap抽象类,实现了Map接口,它们的关系如下:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("key1",10);
map.put("key2",20);
System.out.println(map.put("key3",30));
System.out.println(map.put("key1",40));
System.out.println(map);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# LinkedHashMap
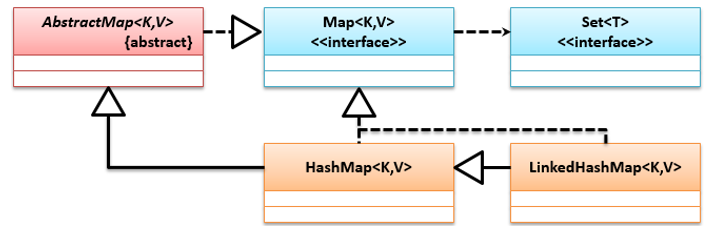
它基于链表实现了键值对存储,保证了集合存储顺序与增加顺序相同,它是HashMap子类,重复实现了Map接口,它们的继承关系如下:
import java.util.LinkedHashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new LinkedHashMap<String, Integer>();
map.put("key1",10);
map.put("key2",20);
System.out.println(map.put("key3",30));
System.out.println(map.put("key1",40));
System.out.println(map);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# Hashtable
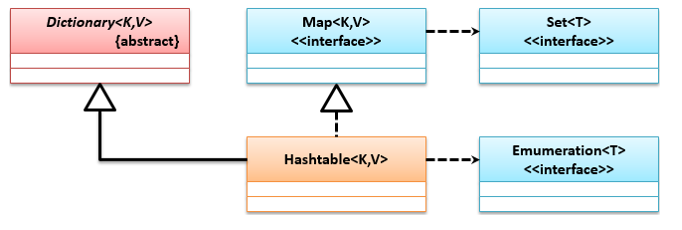
该类从JDK 1.0时就提供了,它是Dictionary的子类,在JDK 1.2时让其多实现了一个Map接口,它们的继承关系如下:
import java.util.Hashtable;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new Hashtable<String, Integer>();
map.put("key1",10);
map.put("key2",20);
System.out.println(map.put("key3",30));
System.out.println(map.put("key1",40));
System.out.println(map);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
注意HashMap中的方法都是异步操作,是非线程安全的,它允许保存null数据。而HashTable中的方法都是同步操作,是线程安全的,不允许保存null数据。
# TreeMap
TreeMap是有序Map集合类型,可按照key进行排序,需要被保存对象实现Comparable接口,它们的类继承结构如下:
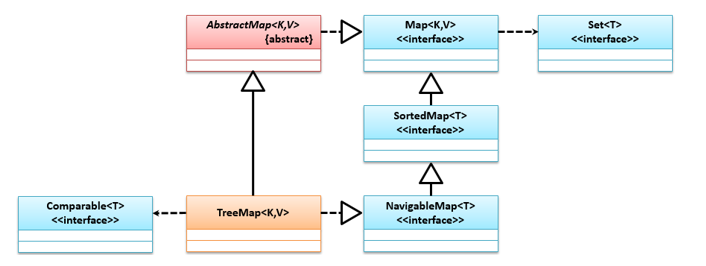
import java.util.Map;
import java.util.TreeMap;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<String, Integer>();
map.put("key1",10);
map.put("key2",20);
System.out.println(map.put("key3",30));
System.out.println(map.put("key1",40));
System.out.println(map);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
# Map.Entry
在Map集合中Map.Entry是操作键值对的标准接口,从JDK 1.9开始可以直接利用Map接口,以HashMap为例,它们的关系结构如下:
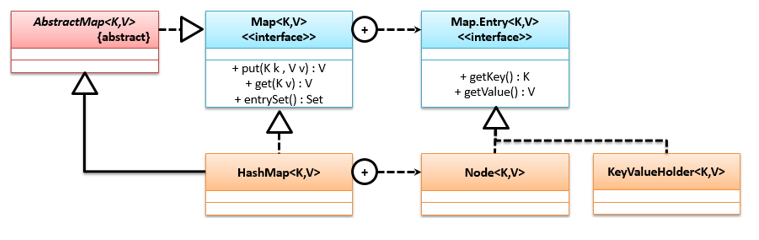
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map.Entry<String, Integer> entry = Map.entry("MyKey", 100);
System.out.println("获取的Key为:"+entry.getKey());
System.out.println("获取的Value为:"+entry.getValue());
System.out.println("该类为:"+entry.getClass().getName());
}
}
2
3
4
5
6
7
8
9
10
集合的数据输出是基于Iterator接口的,Collection接口提供iterator方法获取Iterator接口实例,而Map接口中保存的是多个Map.Entry,要输出它们需要:
- 使用Map接口的entrySet(),将Map变为Set集合。
- 使用iterator()方法取得Iterator的实例化对象。
- 通过Iterator迭代到每一个Map.Entry对象,进行key和value分离。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("key1",10);
map.put("key2",20);
System.out.println(map.put("key3",30));
System.out.println(map.put("key1",40));
System.out.println(map);
Set<Map.Entry<String, Integer>> set = map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator = set.iterator();
while(iterator.hasNext()) {
Map.Entry<String, Integer> oneEntry = iterator.next();
System.out.println(oneEntry.getKey()+" = "+oneEntry.getValue());
}
System.out.println();
for(Map.Entry<String, Integer> entry:set) {
System.out.println(entry.getKey()+" = "+entry.getValue());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
将Map应用于自定义类时,需要重写hashCode()和equals()方法。
# Stack栈
栈是先进后出(First In Last Out,FILO)存储模式,栈结构中有栈顶和栈底,只能在栈顶操作,入栈就是在栈顶压入元素,出栈就是从栈顶弹出元素。
栈的类继承结构如下:
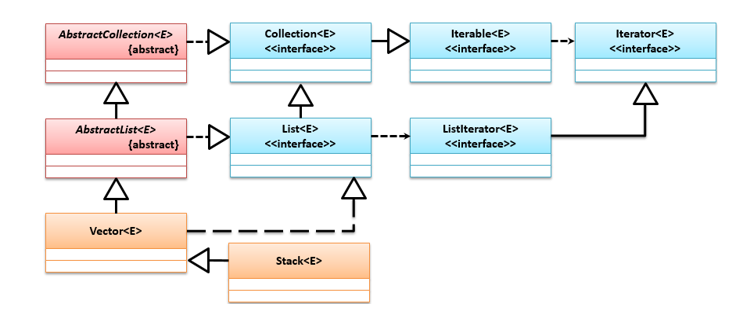
import java.util.Stack;
public class Main {
public static void main(String[] args) {
Stack<String> stackStr = new Stack<String>();
stackStr.push("A");
stackStr.push("B");
stackStr.push("C");
System.out.println(stackStr.pop());
System.out.println(stackStr.pop());
System.out.println(stackStr.pop());
System.out.println(stackStr.pop());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Queue和Deque
队列(Queue)是一种先进先出(First In First Out,FIFO)的线性数据结构,所有数据在队尾添加,在队首取出,JDK 1.5中提供Queue接口实现单端队列操作标准,Deque是双端都能进行操作的数据结构,它是Queue的子接口,在JDK 1.6时添加,它们的类继承关系如下:
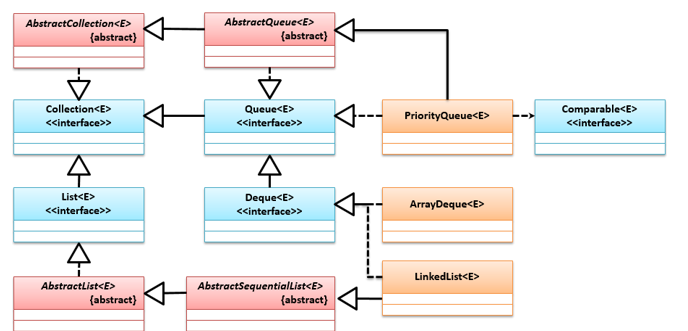
import java.util.Deque;
import java.util.LinkedList;
import java.util.PriorityQueue;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<String> queue = new PriorityQueue<String>();
queue.add("1");
queue.add("2");
queue.add("3");
queue.offer("4");
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.poll());
Deque<String> deque = new LinkedList<String>();
deque.add("1");
deque.add("2");
deque.add("3");
deque.offerFirst("4");
System.out.println(deque);
System.out.println(deque.getLast());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
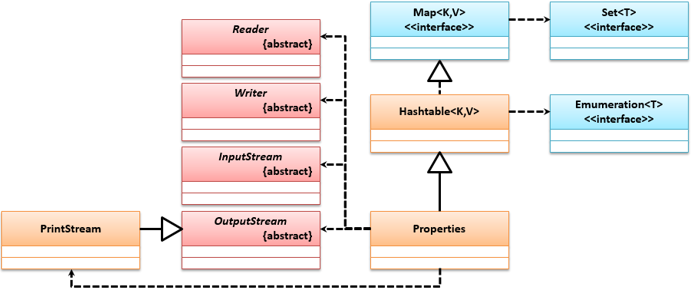
# Properties属性
属性是字符串的键值对,在Java中使用Properties类操作,Properties虽然是Hashtable的子类,但它的数据类型只能是String,它们的类关系结构如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
public class Main {
public static void main(String[] args) {
Properties prop = new Properties();
prop.setProperty("name", "xie");
prop.setProperty("age", "18");
System.out.println(prop.getProperty("name"));
try {
prop.store(new FileOutputStream(new File("test.properties")), "personal info!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Properties prop2 = new Properties();
try {
prop2.load(new FileInputStream(new File("test.properties")));
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(prop2.getProperty("age"));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
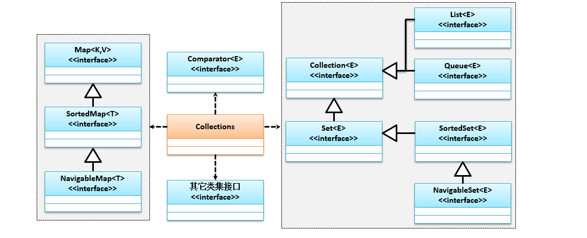
# Collections工具类
Collections是专门给集合提供的工具类,它实现Collection,Map,List,Set,Queue等集合操作,它的类关系结构如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> listInteger = new ArrayList<Integer>();
Collections.addAll(listInteger, 45,34,76,12);
System.out.println(listInteger);
Collections.reverse(listInteger);
System.out.println(listInteger);
System.out.println(Collections.binarySearch(listInteger, 45));
listInteger.sort((a,b)->{
return a-b;
});
System.out.println(listInteger);
System.out.println(Collections.binarySearch(listInteger, 34));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
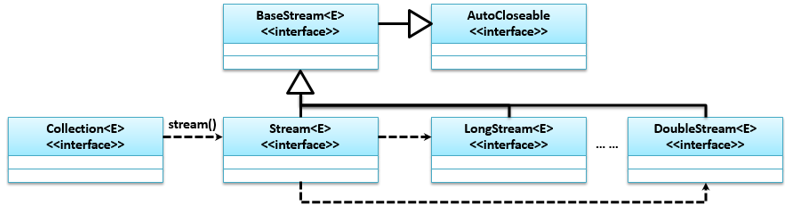
# Stream
Stream是从JDK 1.8后提供的一种数据流的分析操作标准,利用它与Lambda结合进行数据统计操作,类关系结构如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
List<Integer> arrayList = new ArrayList<Integer>();
Collections.addAll(arrayList, 45,12,32,53,64,32);
Stream<Integer> stream = arrayList.stream();
System.out.println(stream.filter((ele)->ele.equals(32)).count());
List<String> strList = new ArrayList<String>();
Stream<String> stream2 = strList.stream();
Collections.addAll(strList, "Java","Javascript","hlJsn","JSP","Json");
List<String> resultList = stream2.filter((ele) -> ele.toLowerCase().contains("j")).skip(1).limit(3).collect(Collectors.toList());
System.out.println(resultList);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# MapReduce
MapReduce是一种分布式计算模型,最初由Google提出,主要用于搜索领域,解决海量计算问题,MapReduce模型一共分为两部分:map(数据处理)与reduce(统计计算),在Stream中可以利用MapReduce对集合中的数据进行分析。
import java.util.ArrayList;
import java.util.DoubleSummaryStatistics;
import java.util.List;
class Order{
String nameString;
double unitPrice;
int amount;
public Order(String name,double price,int a) {
nameString=name;
unitPrice=price;
amount=a;
}
}
public class Main {
public static void main(String[] args) {
List<Order> orderList = new ArrayList<Order>();
orderList.add(new Order("apple", 3, 10));
orderList.add(new Order("banana", 2, 4));
orderList.add(new Order("my_orange", 5, 7));
orderList.add(new Order("my_bag", 2.5, 5));
orderList.add(new Order("my_pen", 3, 5));
DoubleSummaryStatistics stat = orderList.stream()
.filter((ele)->ele.nameString.toLowerCase().startsWith("my_"))
.mapToDouble((orderObject)->orderObject.unitPrice*orderObject.amount)
.summaryStatistics();
System.out.println("购买物体种类:"+stat.getCount());
System.out.println("购买总价:"+stat.getSum());
System.out.println("最高价格:"+stat.getMax());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34